Overview
이번 섹션에서는 통계가 어떻게 활용되는지에 대한 전반적인 landscape을 소개하고자 하며, 이는 다양한 통계적 분석 이론들 속에서 자신이 수행하고 있는 분석의 적절성을 대략 이해하며, 어떤 부분이 부족한지를 파악할 수 있도록 하고자 함.
여기에서 소개하는 내용을 모두 수업에서 다룬다는 것은 절대 아님!
통계 분석은 크게 세 가지 주제로 나눌 수 있음.
- Associations: 변수들 간의 관계를 파악; regression coefficient
- Strength of associations: 그 관계의 크기, 예측의 정확성; R-squared, correlation coefficient, effect size
- Inference: 그 관계와 크기가 모집단에서는 어떠할지 추론; confidence interval, p-value
통계가 활용되는 방식을 분류하면,
- 기술적 분석 (descriptive)
- 변수들 간의 진실한 관계를 분석 (relational)
- 인과 관계의 파악과 개입 (causal/intervention)
Descriptive: 기술적 분석
통계청의 조사 결과와 같이 현상에 대한 기술
단순한 기술은 자칫 오해의 여지와 호도할 위험이 존재
예를 들어,
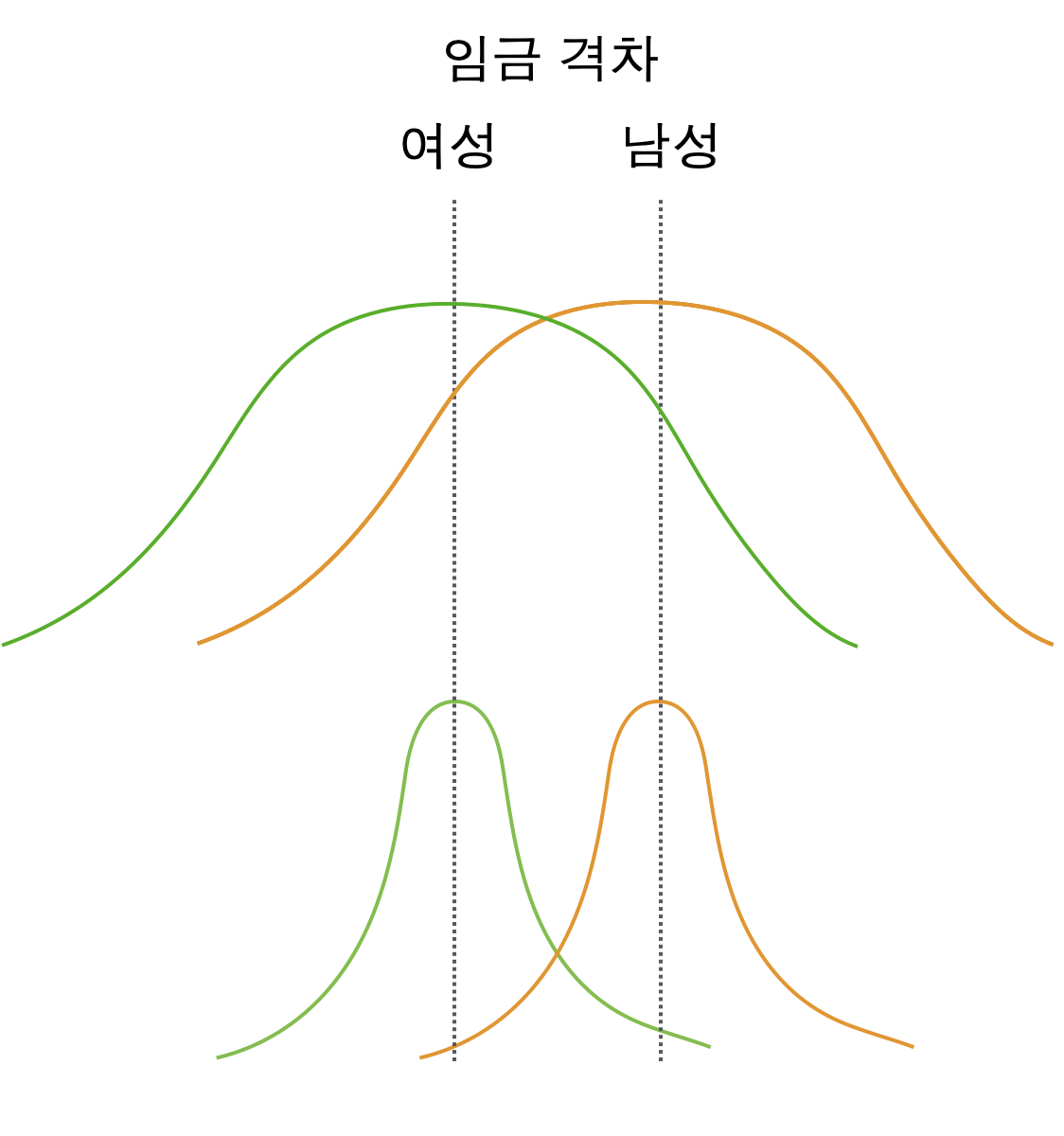
- 남녀 임금의 차이에 대한 통계치를 제시하는 경우
- 외국의 경우, 인종별 범죄율에 대한 통계치 등등
만일, 좀 더 자세히 나눠어서, 연령별, 직업군별로 남녀 임금의 차이를 본다면 만족스러운가?
얼마나 더 상세히 나누어야 하는가?
그 차이는 의미있는 차이인가?
Relational: 변수들 간의 진실한 관계를 분석
Case 1
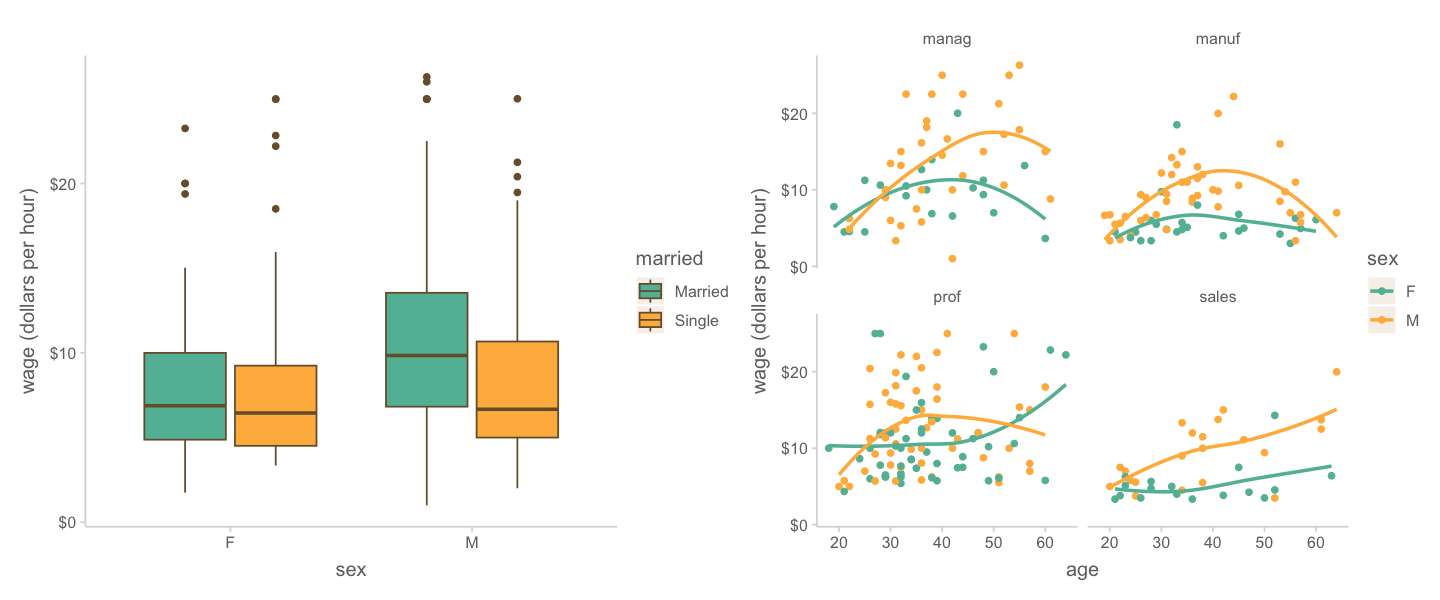
미혼자에 대한 임금 차별이 있는가? 차별이 의미하는 바는 무엇인가?
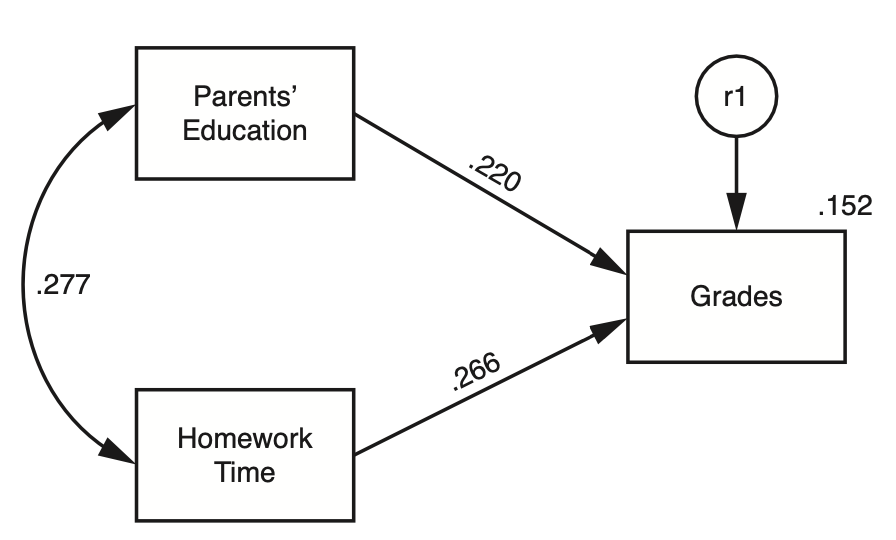
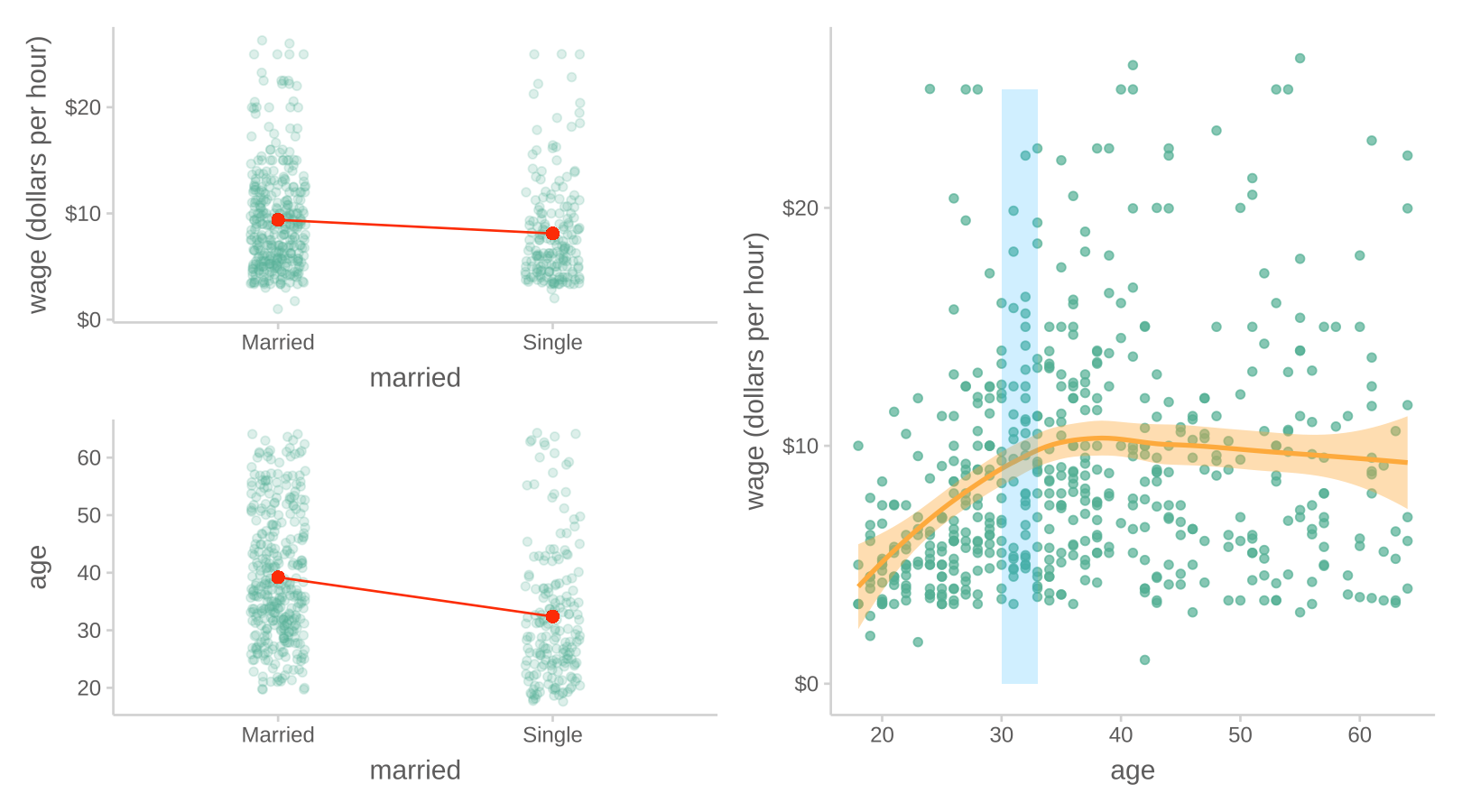
아래 첫번째 그림과 같이 기혼자의 임금이 미혼자에 보다 높은 것으로 나타났다면,
이는 정말 결혼하지 않은 것이 임금을 책정하는데 영향을 주었는가?
하지만, 당연하게도 기혼자는 미혼자에 비해 연령이 높으며 (두번째 그림),
높은 연령은 연차가 높거나 실무능력이 뛰어난 경향으로 인해 임금을 높을 수 있다는 것을 감안하면 (세번째 그림)
차별처럼 보이는 차이는 차별이라고 볼 수 없을 수도 있음.
다시 말하면, 연령을 고려한 후에도 기혼자의 임금은 미혼자보다 높은가?
여전히 높다면, 연령을 고려한 후 혹은 연령을 조정한 후(adjusted for age)의 차이는 얼마라고 봐야하는가?
연령을 고려한 임금 차이를 조사하는 방법은 무엇이 있겠는가?
- 연령별로 나누어 비교?
Data from the 1985 Current Population Survey
연령을 고려한 마라톤 기록?
70세 노인과 20세 청년이 동일하게 2시간 30분의 기록을 세웠다면?
- “나이 차이가 큰 두 사람의 기록을 비교하는 것은 공평하지 않아”
- 나이를 감안한 마라톤 실력?
- 다시 말하면, 나이와는 무관한/독립적인 마라톤 능력에 대해 말하고자 함
- 이는 동일한 나이의 사람들로만 제한해서 마라톤 기록을 비교하는 것이 공평한 능력의 비교라고 말하는 것과 같은 이치임
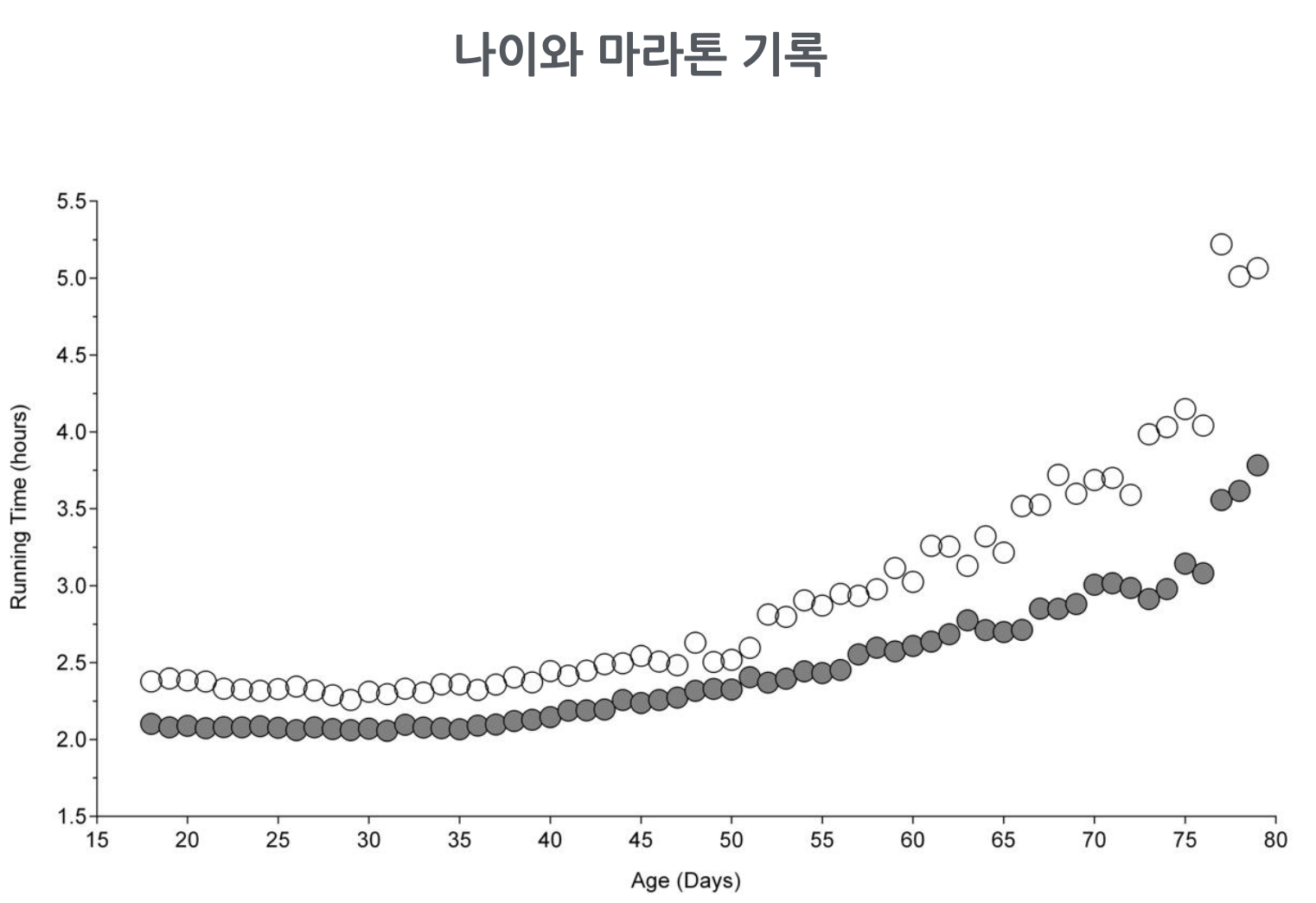
Source: https://doi.org/10.1186/2052-1847-6-31
Case 2
기혼여부에 따른 임금의 차이가 남녀별로 다른가?
연령이 올라감에 따라 임금이 올라가는 패턴에 차이가 있는가?
왼편 그림에서 보면, 기혼여부에 따른 임금의 차이가 남녀에 따라 다르게 나타나는 것으로 보임
이러한 현상을 변수 간에 상호작용(interaction)이 있다고 말함 (moderate라는 표현도 있음)
말하지면, 기혼여부가 임금에 주는 효과가 성별에 따라 바뀌고, 기혼여부와 성별이 상호작용하여 임금에 영향을 준다라고 표현할 수 있음 (2-way interaction)
비슷하게, 오른편을 보면, 연령에 따른 임금의 증가 패턴이 남녀에 따라서, 업종에 따라 다르게 나타나는 것으로 보임
(manag: management, manuf: manufacturing, prof: professional)
즉, 연령이 임금에 미치는 효과는 성별과 업종에 따라 바뀌고, 연령, 성별, 업종이 상호작용하여 임금에 영향을 준다라고 표현할 수 있음 (3-way interaction)
Warning
위의 표현은 모두 효과를 가정한 표현으로 설명을 위해 편의상 그렇게 표현하였음
또한, 다른 요소들은 단순화를 위해 생략했음. 예를 들어 왼편의 상황에서 나이를 고려하면 다른 양상을 보일 수 있음
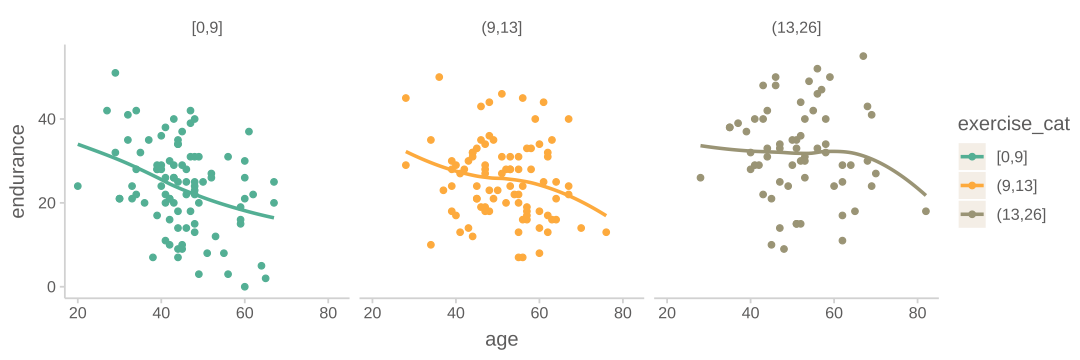
또 다른 예로는, 나이가 듦(age)에 따라 지구력(endurance)의 감소가 강도 높은 운동을 한 기간(년수)(exercise)에 따라 변화한다는 가설을 테스트한 자료
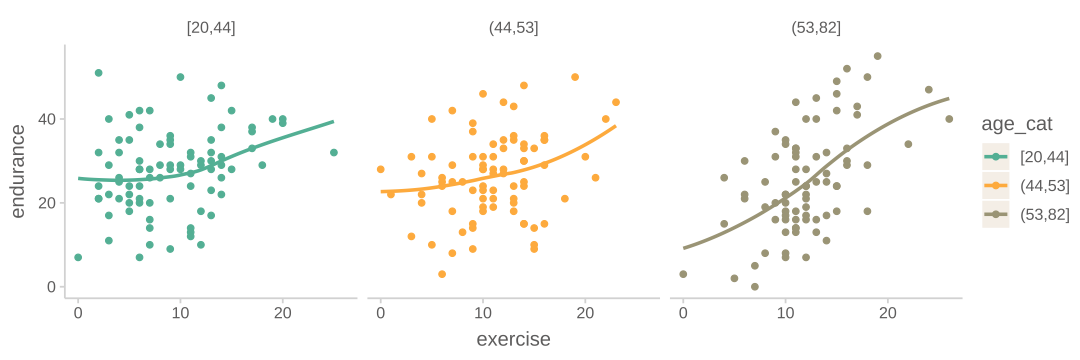
이 경우 운동을 한 기간은 앞의 예에서처럼 카테고리 변수가 아니기 때문에 임의로 3구간으로 나누어 살펴 본 것임.
나이가 지구력에 미치는 부정적 영향이 운동을 한 기간에 따라 변하는 것으로 보임.
즉, 나이와 운동기간이 상호작용하여 지구력에 영향을 미친다고 표현할 수 있음
상호작용은 아래와 같이 상호작용하는 두 변수의 위치를 바꿔 살펴볼 수도 있음
Important
시각화를 통해 전반적인 패턴을 살펴보는 것은 통계적 모형을 세워 수학적으로 분석하기 전에 하는 보조 수단임.
앞에 마라톤 기록의 예처럼 실제 분석은 한 변수를 고려한 후 다른 변수의 변화를 계산하는 방식으로 분석을 하는 것이지, 나이별로 자료를 나누어 보지 않듯이, 운동기간을 위에서처럼 구간으로 쪼개어 분석하는 것은 아님.
Case 3
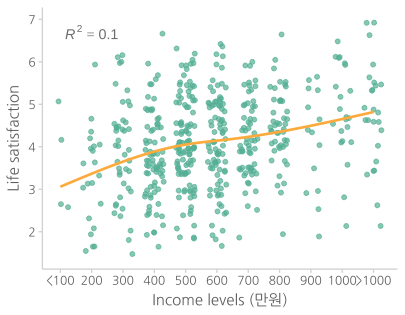
임금이 증가하면 삶의 만족도가 높아지는가? 아마도?
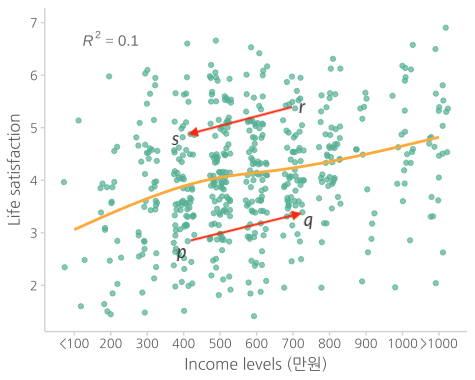
하지만, 특정 A의 임금이 p 에서 q 로 증가할 때, 트렌드대로 움직이겠는가?
혹은, 특정 B의 임금이 r 에서 s 로 감소할 때, 트렌드대로 움직이겠는가?
개인의 변화를 살펴보는 종단연구(logitudinal)로 그 갭을 채울 수 있음
Note
Longitudinal (종단) vs. cross-sectional (횡단)
종단 데이터는 관측의 단위, 예를 들어 개인을 반복측정하여 개개인의 특성을 함께 파악할 수 있는 장점을 가짐. 시간과 비용이 많이 들고, attrition (참여자 탈락) 비율이 높아질 우려가 있어 분석에 걸림돌이 되곤 함. 특히, 노인에 대한 연구는 사망으로 인해 참여자가 주는데, 이런 결측치를 고려한 분석에는 상당한 조심성과 기술이 요함. (missing data analysis)
분석의 관점에서 보면, 개인을 반복 측정하기 때문에 측정값들 사이의 dependency 문제가 생기는데 이를 분석에 고려하려는 노력임. 참여자 각각의 고유한 특성과 연구자가 측정하고자 하는 특성을 분리하고자 함. 위의 예에서 보면, “임금이 삶의 만족도에 주는 영향”과 “개개인의 고유한 특성이 삶의 만족도에 주는 영향”을 분리시켜야 전자의 효과를 분명히 파악할 수 있음. 이는 이후 언급할 multi-level analysis로도 볼 수 있음.
반면, 주로 접하게 되는 횡단 데이터는 모든 관측치가 independent, 즉 서로 영향을 받지 않는다고 가정할 수 있는데, 물론 한 가족의 구성원이 참여하는 연구는 그 가정에 위배됨.
횡단데이터의 문제는 소위 cohort bias가 숨어 있을 수 있음. 예를 들어 다른 나이대의 사람들은 다른 사회적 경험을 통해 다른 특성을 지녔을 수 있으므로, 데이터의 관측치들이 homogenous (동질적) 하지 못함으로 인해 연구자가 보려는 관계에 노이즈를 만들 수 있음.
하지만, 그럴지라도 임금으로 “인해” 삶의 만족도가 올라가느냐는 다른 문제임 >> 인과관계의 문제
- 예를 들어, 연봉의 증가가 삶의 만족도를 올렸다기 보다는 상대적 비교에서 오는 자존감이 증가했기 때문일 수 있음
- 연봉이 높은 곳은 직업 특성이 다를 수 있음
- 또는, 인맥과 인간관계의 변화에서 오는 차이일 수도 있음
다른 시각에서 보면, 인과 관계를 가정하더라고 개입(intervention)하는 것은 또다른 문제임: 개입은 인과의 매커니즘을 교란시킬 수 있음.
예를 들어, 현재 A의 연봉 2천만원을 갑자기 4천만으로 올리면 삶의 만족도가 트렌드대로 0.8pt 올라가겠는가?
- 연봉의 증가는 주변의 시기와 질투를 가져와 인관관계에 영향을 줄 수 있음
- 본인의 자만은 여러 부정적 결과를 초래할 수 있음
- 노력에 의해 얻은 것이 아니라는 점은 다른 부작용을 낳을 수 있음
Prediction vs. intervention
- A의 임금이 올라가면 삶의 만족도가 따라서 올라갈 것이라고 (조심스럽게) 예측할 수는 있으나: association
- 좀 더 정확히 말하면, 임금이 높은 것은 삶의 만족도가 높은 것과 연관이 있다라고 표현
- “올라가면”이라는 표현은 시간 개념을 포함한 것이라 횡단(cross-sectional) 데이터에서는 부적절
- A의 임금을 올리면 삶의 만족도가 올라갈 것이라고 단정할 수 없음: causal
- Intervention이 효과가 있으려면, 적어도 진정한 관계를 파악해야만 하며, 더 나아가 메커니즘을 포함한 인과관계가 만족해야 함.
- 진정한 관계의 문제와 인과의 문제는 서로 엮여 있으며 복잡한 문제임.
- 예를 들어, 오렌지를 섭취하면 괴혈병이 예방되나 사실은 비타민 C의 섭취가 괴혈병을 예방하는 것임
만약, 장거리 항해에서 상급자(높은 연령)에게만 과일이 제공되었을 때, 나이가 많은 선원들에게서 괴혈병이 덜 생겼다는 현상으로부터 연령과 괴혈병의 관계를 추론해서는 안됨. 하지만 예측은 여전히 유효함.
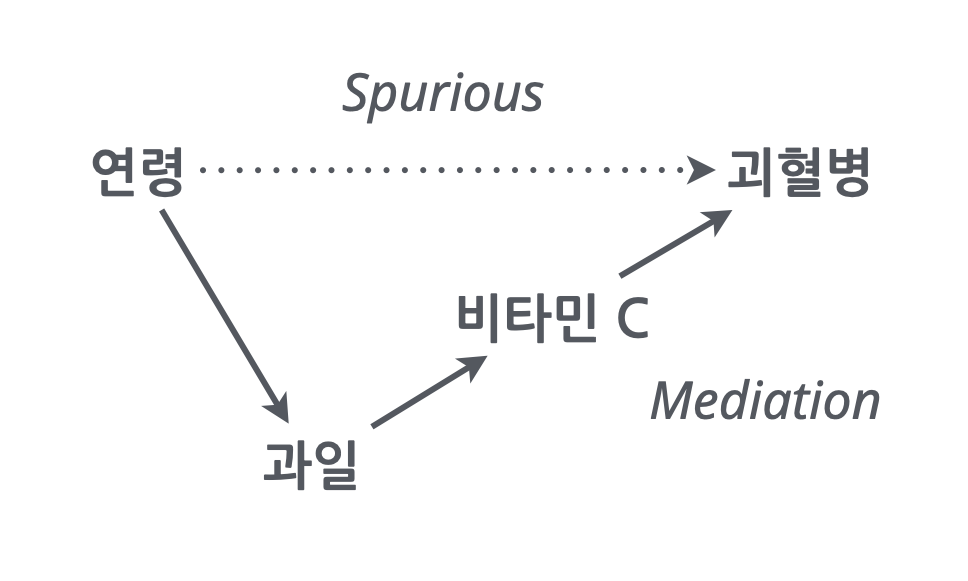
- 또는, 신앙심이 깊은 노인들의 수명이 더 길다는 현상이 관찰되었을 때, 신앙심 자체가 심리적으로나 신체적으로 긍정적인 효과를 가질 수 있으나, 그 외에도 신앙 활동의 일부로 활동이 늘고 다른 이와의 긍정적 교류가 건강에 영향을 미쳤을 수도 있음.
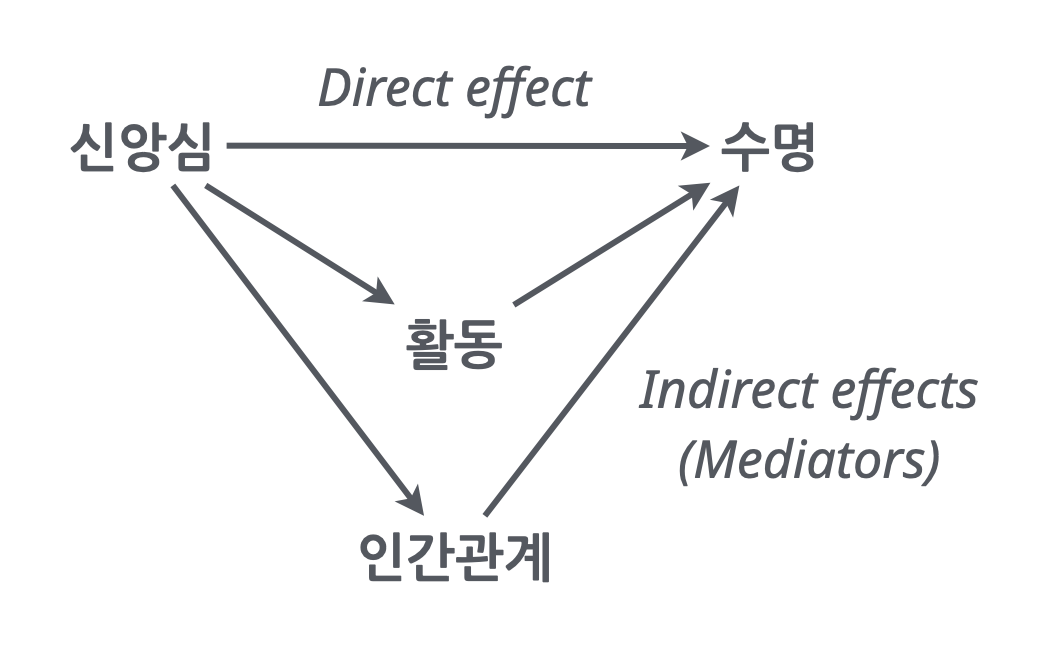
이 때, 신앙심과 수명과는 진정한 관계가 있다고 볼 수 있으나 (not spurious) 그 인과 관계에 대해서도 좀 더 깊은 논의가 필요함.
다시 말하면, 어떤 노인에게 신앙을 권유했을 때, 수명이 연장되었을지라도 신앙심 자체가 수명을 연장시킨 것인가는 별개의 논의임.
- 예를 들어, 오렌지를 섭취하면 괴혈병이 예방되나 사실은 비타민 C의 섭취가 괴혈병을 예방하는 것임
The strength of relationships
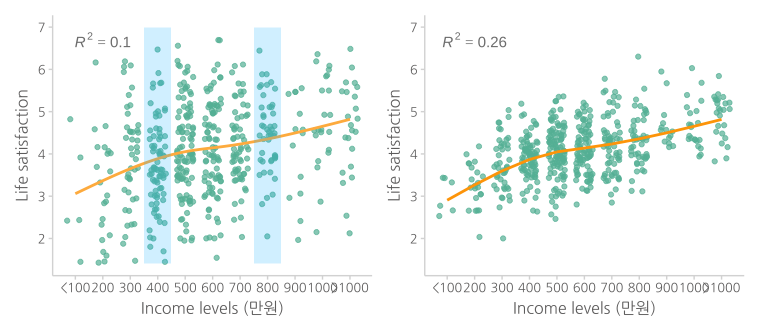
변수들간의 관계와 그 관계의 크기(stength)는 중요하게 구별될 필요가 있음
아래 두 그림은 변수 간의 관계는 동일하나 그 크기에 차이가 있음
오른쪽 그림에서 연봉으로 그 사람의 삶의 만족도 지수를 더 정확히 예측할 수 있으며, 이를 설명력 \((R^2)\)이 높다고 표현
보통 이 효과의 크기가 클수록 인과관계일 가능성은 높다고 볼 수 있으며,
왼쪽 박스에서처럼 variability가 높다는 것은 다른 이유가 있을 가능성이 높음
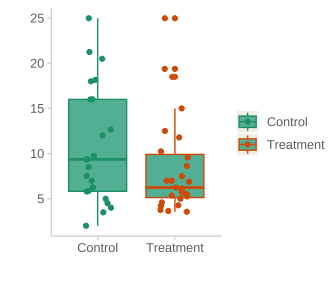
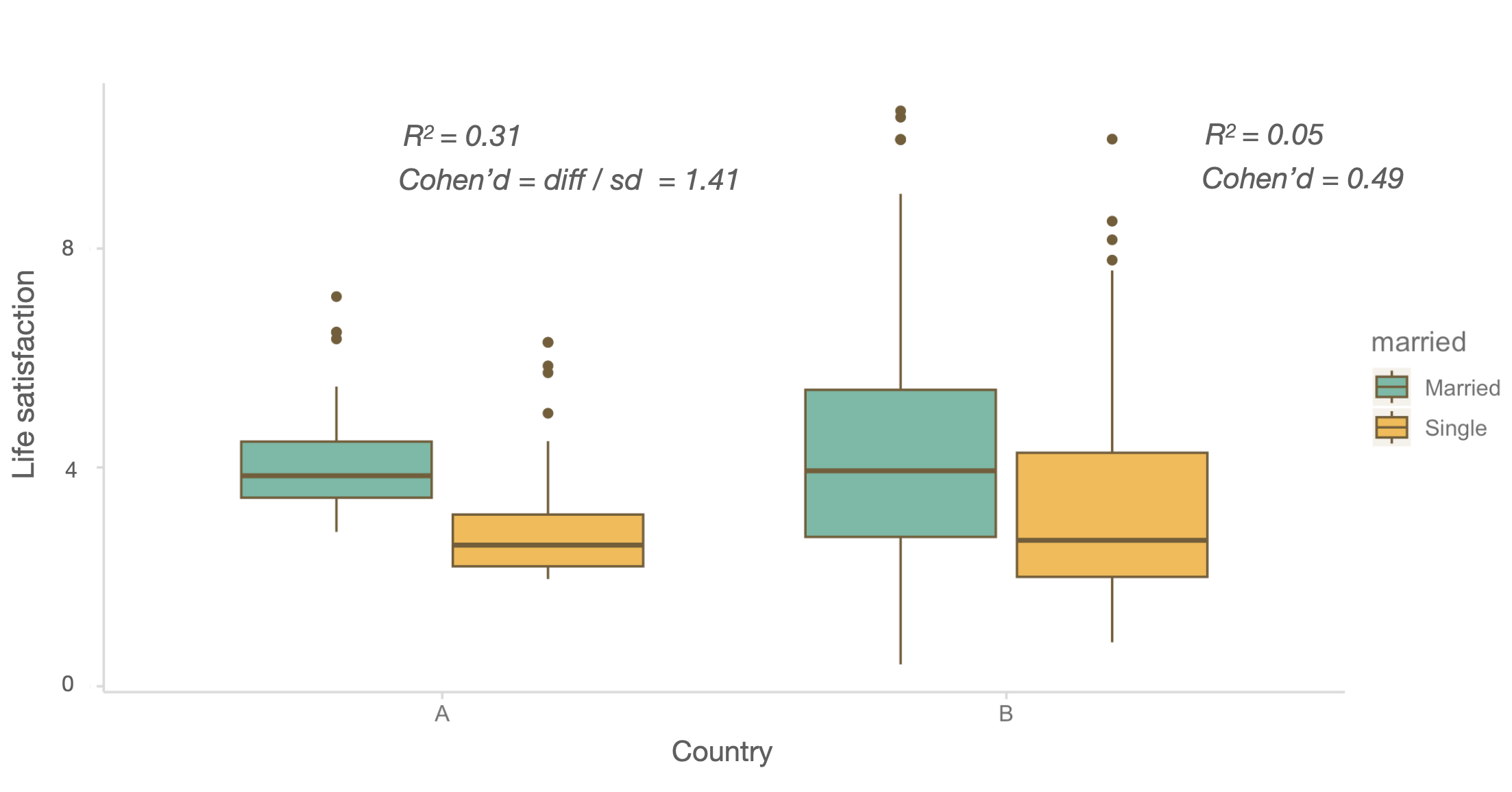
카테고리 변수에 대해서도 비슷하게 생각할 수 있음.
이 경우, 두 그룹 간의 차이에 대한 효과의 크기를 말할 수 있고, \(R^2\) 이외에도 대표적으로 Cohen’s d로 표현할 수 있음.
Note
진정한 관계를 탐구하는 것이 어려움에도 불구하고, 관계성을 파악함으로써 통찰을 얻을 수 있음.
복잡한 변수와의 관계를 풀어내려고 노력
Source: Multiple Regression and Beyond by Timothy Z. Keith
Latent variable model (잠재 변수 모형)
구체적으로 측정한 변수들간의 관계를 넘어서서, 연구자는 좀 더 추상적이고 개념적인 construct에 대해 이론적 논의를 하고자 한다면, 그 construct를 대변해줄 수 있다고 간주되는 측정가능한 요인들로 “잠재 변수”를 구성하여, 그 잠재 변수들 간의 관계를 파악함.
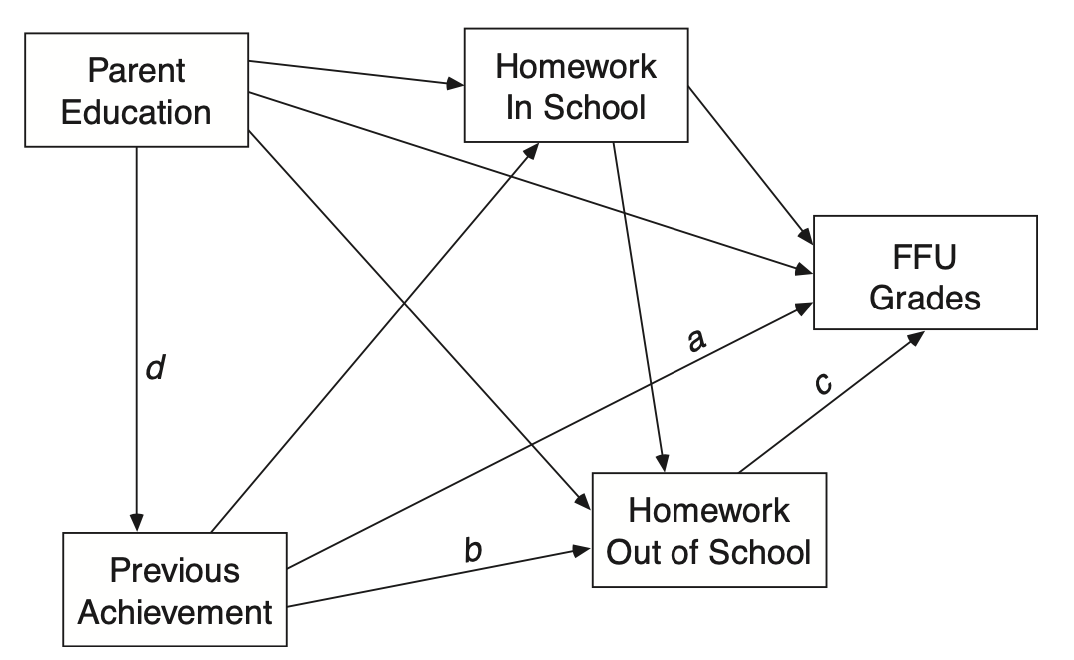
학업성취도에 미치는 요인들
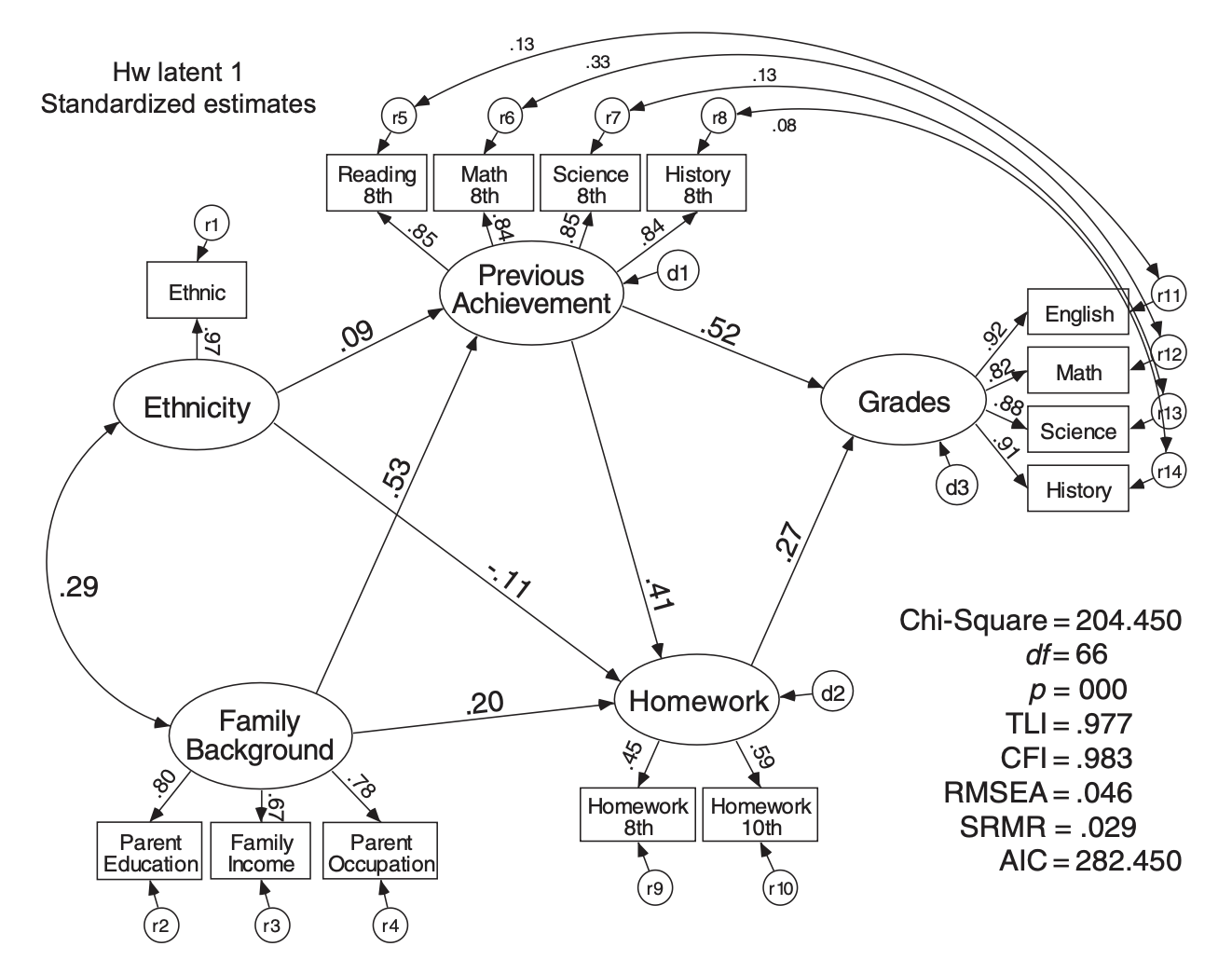
Source: Multiple Regression and Beyond by Timothy Z. Keith사회의 보상체계를 결정하는 요인들
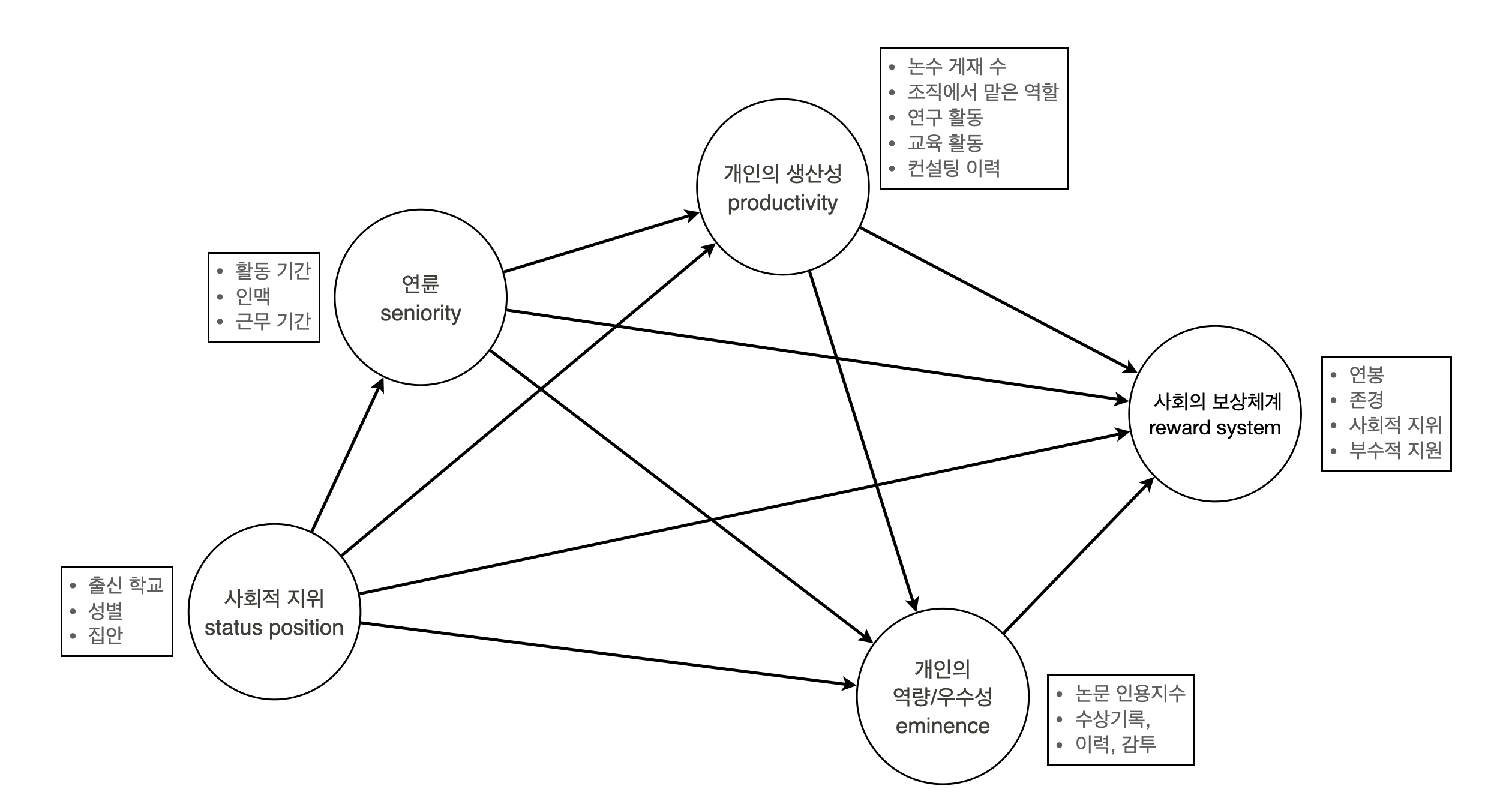
Source: Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences by Jacob Cohen, Patricia Cohen, Stephen G. West, Leona S. Aiken
Causal: 인과관계의 분석
위에서 살펴본 것들은 모두 연구자가 개입하지 않고 관찰만으로 이루어진 분석들임
논의한 것처럼 관찰된 자료로부터 진실된 관계를 파악하는 것은 매우 정교한 분석이 요구되고 많은 요소들을 고려해야 함.
좀 더 분명한 관계를 파악하기 위해 실험 연구가 요구되곤 함
하지만, 많은 경우 실험이 불가능할 뿐 아니라,
실험이 반드시 최선인 것은 아니며, 실험은 나름데로 큰 약점을 갖고 있음.
Confounding
Confounding
일반적으로, 표면적으로 드러난 변수간의 관계가 숨겨진 다른 변수들(lurking third variable)에 의해 매개되어 있어 진실한 관계가 아닌 경우, confounding 혹은 confounder가 존재한다고 함.
사회과학에서 오래된 가장 핵심적인 문제이나 최근까지도 정확히 정의하기 어려움 개념이었음.
Causal inference라는 통계와는 별개의 개념으로 발전되어 최근에야 이론적으로 완성이 되어 관심이 높아짐.
극단적이지만 이해하지 쉬운 예로는
- 초등학생 발 사이즈 → 독해력
- 머리 길이 → 우울증
Answer!

Common cause/Fork
맨 처음 든 예도 마찬가지로 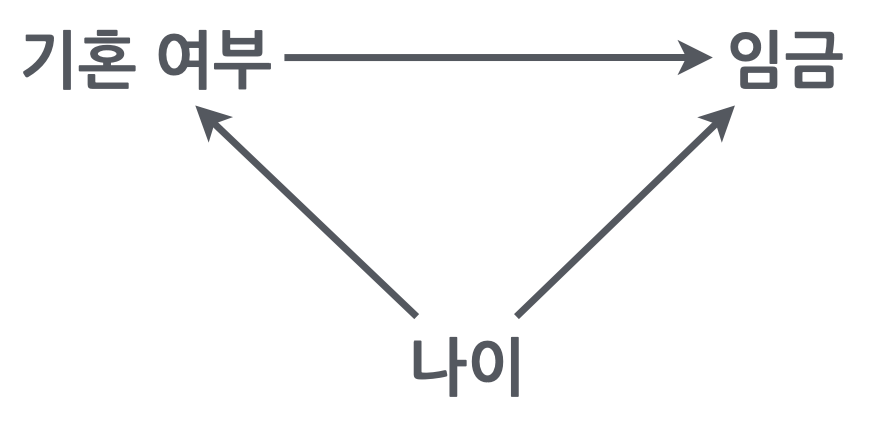
올바른 관계를 파악하려면, 동일한 나이에 대해 그 관계를 파악한 후 각 나이에서의 효과를 (weighted) 평균해서 살펴봐야함
통계에서는 이를 나이를 통제 (control for age)한다고 표현하며, 같은 의미로 다음과 같은 표현을 씀
나이를 고려했을 때; account for age
나이를 조정했을 때; adjust for age
나이를 잔차화했을 때; residualize age
나이의 변량을 넘어서서; above and beyond age
Simpson’s paradox
아래 첫번째 그림은 집단 전체에 대한 플랏이고, 두번째 그림은 나이대별로 나누어 본 플랏
전체 집단을 보면 운동을 많이 할수록 콜레스테롤이 증가하는 것으로 보이나,
나이대별로 보면, 상식적으로 운동이 긍정적 효과가 나타남.
왜 그렇게 나타나는가?
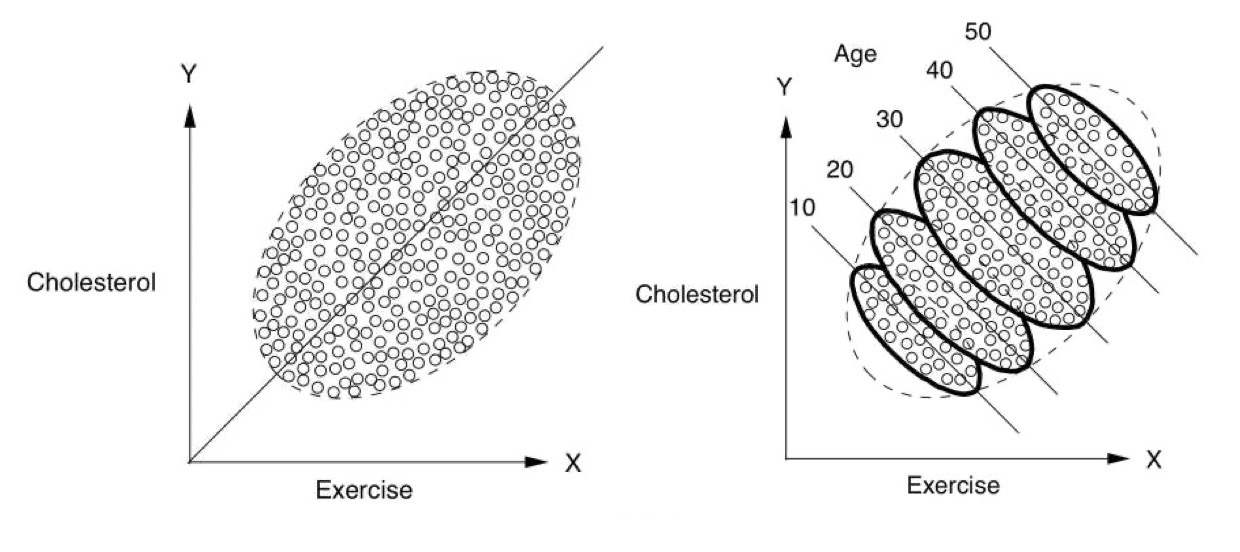
Source: The book of why by Judea Pearl
마지막 예를 들면,
은퇴한 노인들을 대상으로 규칙적인 걷기가 사망율을 감소시킬 것이라는 가설을 확인하기 위해 1965년 이후 8000명 가량의 남성들을 추적조사한 데이터의 일부를 이용했는데,
Source: The book of why by Judea Pearl
- 12년 후 사망율에서 casual walker(하루 1마일 이하)와 intense walker(하루 2마일 이상)가 각각 43%, 21.5%로 나타났음.
- 이 걷기의 효과를 의심케 하는 요소들(confounding)은 무엇인가?
Answers!
- 건강이 나빠 많이 걷지 못했을 수도…
- 많이 걷는 사람은 상대적으로 젊을 수도…
- 많이 먹는 사람이 덜 걸을 수도…
- 술을 많이 먹는 사람이 덜 걸을 수도…
Important
무수히 많이 생각해볼 수 있는 confounding 요소들을 다 고려해야 하는가?
Yes and No!
실제 저자들도 다음과 같이 기술
“Of course, the effects on longevity of intentional efforts to increase the distance walked per day by physically capable older men cannot be addressed in our study.”
이러한 조심성은 의미있느나 너무 과장될 필요는 없음
소위 중요 역할을 할 것으로 의심되는 confounding을 충분히 통계적으로 고려/통제했다면, 충분히 인과관계 혹은 intervention을 제안할 수 있으며,
그러한 연구는 어떤 요소들을 고려했는지에 대해 밝힘으로써 추후 연구에서 어떤 부분이 더 추가적으로 고려되야 할지 알 수 있게 함.
관찰 데이터로부터 진정한 관계를 파악하기 위해서는 이와 같은 인과 추론이라는 좀 더 큰 프레임에서 분석해야 하며, 통계 안에서 해결하기 어려움.
예를 들어, collider인 경우 통제하면 spurious association이 생길 수 있음.
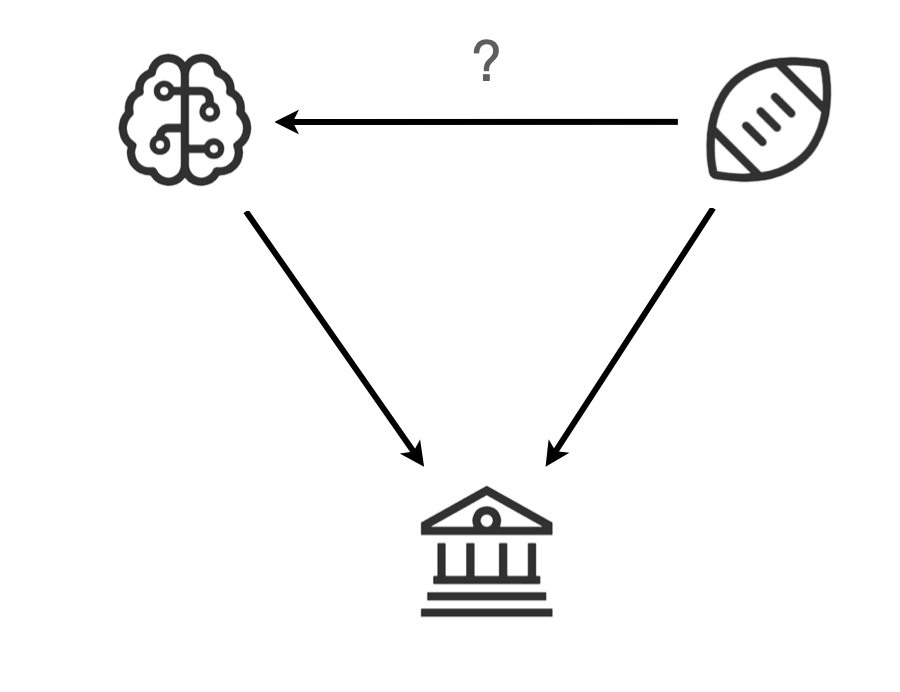
Collider/Immorality
운동능력이 뛰어나면 지능이 떨어지는가?
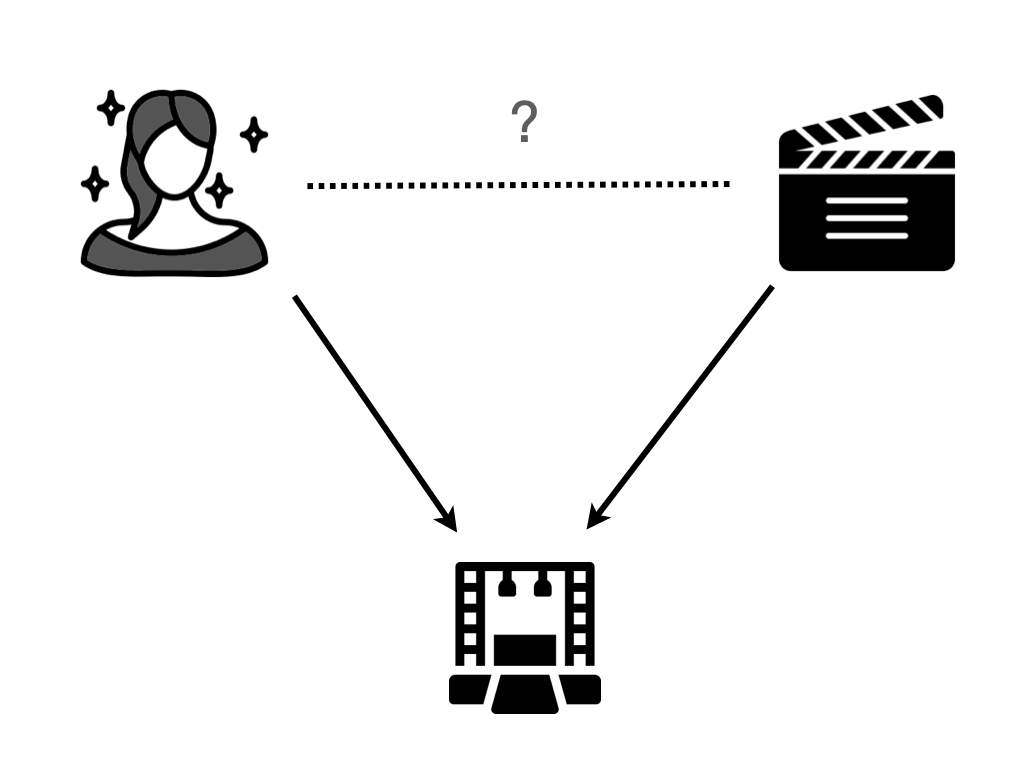
미모가 뛰어나면 연기력이 떨어지는가?
Mediations/Chains(Mechanisms)
- 1990년대 최악의 시카고 공립학교의 개혁 정책
- 고1에서 보충 과목을 없애고, 대학 진학 준비 과목을 수강하도록 함.
- 이 중 대수 1 과목(“Algebra for All”)의 경우 3년 간 유의한 성적 개선이 없었음.
- Guanglei Hong(시카고대 인간발달)은 정책의 직접적 효과는 존재한다고 판별했음!
- 정책이 두 가지 방식으로 (다른 방향으로) 작용했음.
- 이후 “Double-Dose Algebra”으로 개선했음.
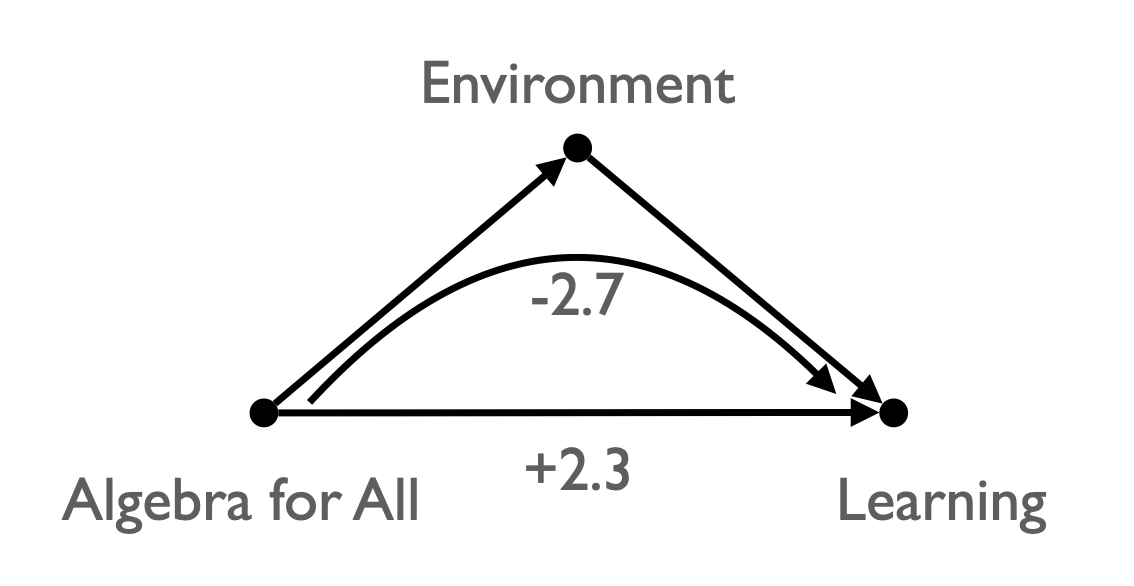
학생들의 과제는 성적에 영향을 주는가?
Source: National Education Longitudinal Study of 1988 (NELS:88)
Directed acyclic graph (DAG)
인과 관계 다이어그램
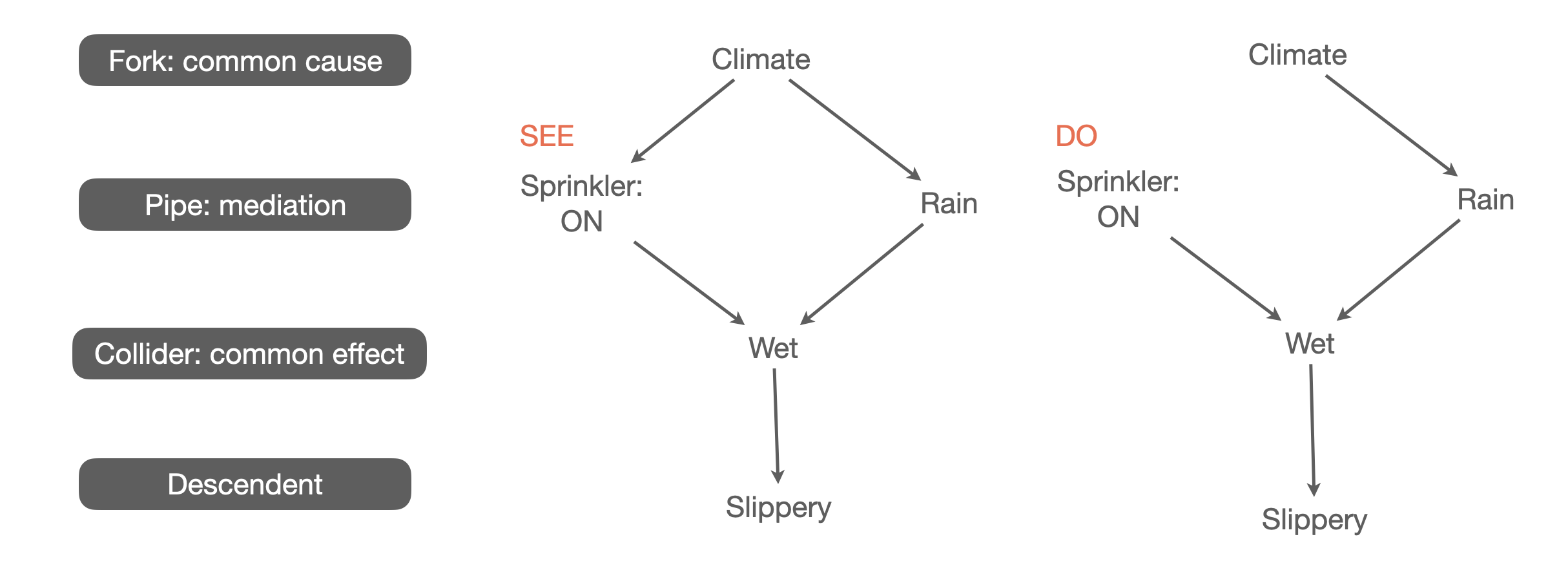
Source: Causality: Models, Reasoning, and Inference (2000) by Judea Pearl
Selection Bias
수집된 데이터의 특성에 따라 인과추론을 방해하거나(confounding); internal validity(내적 타당도)
일반화할 수 있는 대상의 범위가 제한됨; external validity(외적 타당도)
- 노인에 관한 데이터: 누가 사망했는가?
- Survival bias: 일종의 collider bias
- 예를 들어, 비만이 사망율에 미치는 효과에 대한 과소추정
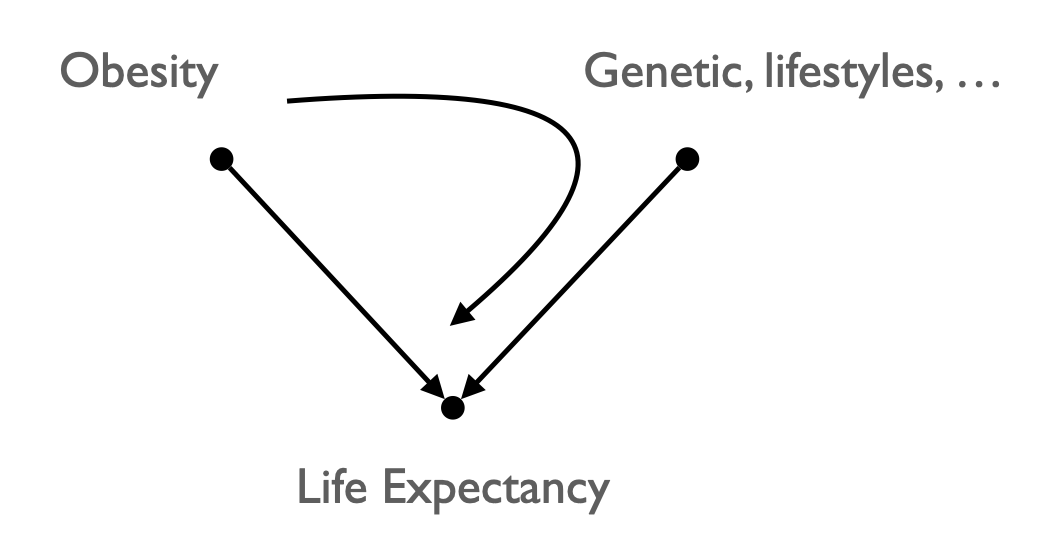
- 의료 분야에서 발견되는 패러독스
- 비만은 당뇨 환자에게 이익이 되는가?
- 과거 기록을 이용?; 수녀들의 자서전 연구
- 추적조사/종단연구(longitudinal study)
- 회사 구성원에 대한 조사: 근속년수에 따른 샘플 속성의 변화
- 누가 참여(안)했는가? 어떤 방식으로 참여했는가?
- 관측되지 않은 데이터: 어떤 사람/대상이 왜 누락되었는가?
- 어떤 사람들이 설문/실험에 참여했는가? 혹은 어떤 문항에 응답했는가?/하지 않았는가?
- 어떤 유저들의 데이터인가? 가령, SNS의 기록은 누가 남기는가?
- 코호트/특정세대의 특성: 그들만의 특성인가?
Abraham Wald: “Where are the missing holes?”
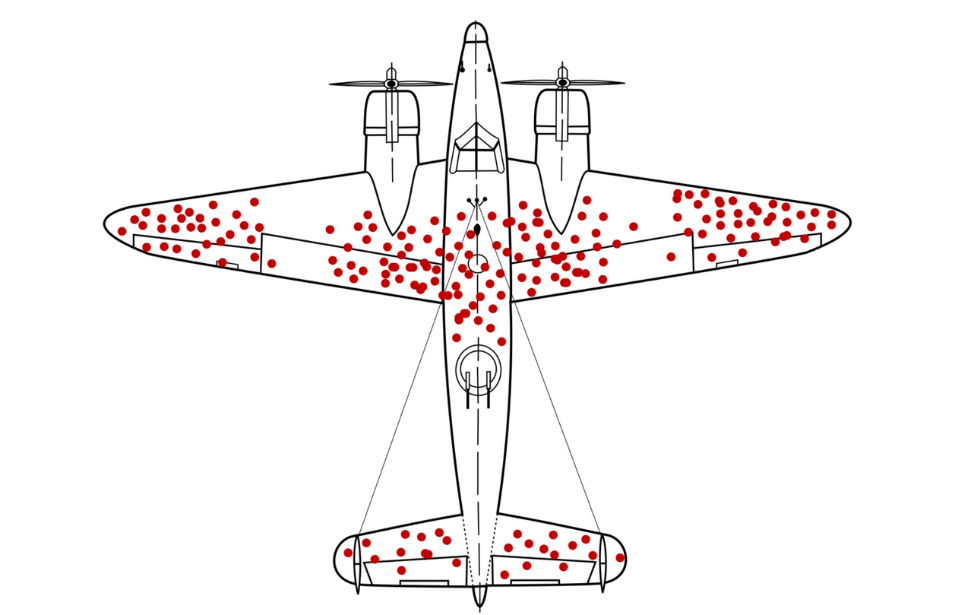
Experimental study
앞서 살펴본 관찰 연구들이 모두 confounding의 위험을 안고 있기에 결정적인 인과관계를 파악하기 위해, 전통적으로 “통계학”의 시각에서 인과문제에 대해서는 보통 임상테스트에서 실시하는 RCT (randomized controlled trial)라고 부르는 소위 gold standard한 실험 연구를 통해서 해결하고자 했음
개념적으로는 물리적 통제라고 볼 수 있으며, 두 그룹으로 집단을 randomly assign(무선/무작위 배정/할당)하면 모든 면에서 동질한 성향을 가짐. 예를 들어, 두 집단의 연령이 평균적으로 동일해짐.
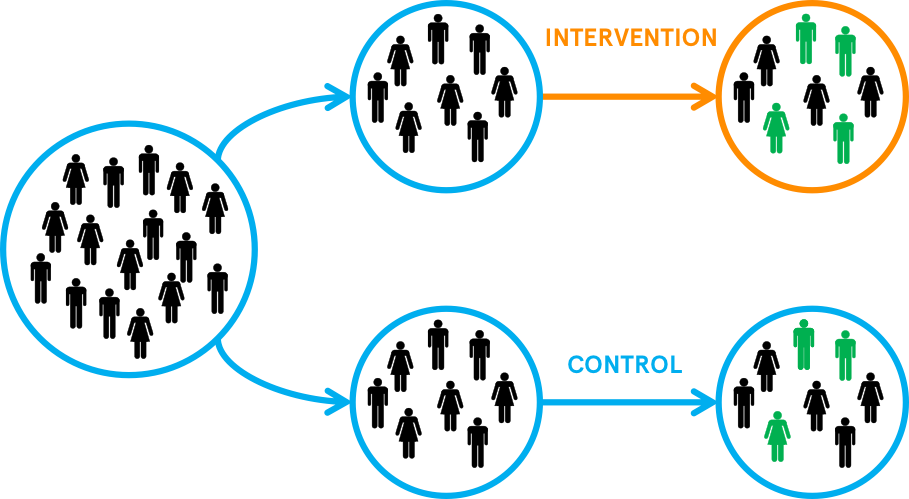
Source: The whats and whys of RCTs
앞서 든 예에서, 걷기가 사망율에 미치는 효과를 검증하려면, 가령 600명을 300명씩 두 그룹으로 무작위로 나눈 후 한쪽은 1마일 이하를 걷도록 하고 나머지는 2마일 이상을 걷게 한 후 12년 후 사망율을 확인해야 함.
분야마다 효과를 제대로 검증하기 위한 많은 실험 설계들이 발전되었음 >> 연구방법론
그럼에도 불구하고, 실험 연구는 자체로 한계를 지님
- 많은 경우 실험이 불가능하거나 완전한 통제가 어려움
- 실험에서 처치한 구체적인 상황에서만 유효하고; 어느 지형을 어느 속도로 누구와 어떻게 걸었는지에 대한 실험 통제하에서
- 따라서 그 효과 또한 일반화되어 표현하기 어려움
- 반대로, 덜 통제된 실험의 경우 어떤 요인의 효과인지 불분명
- 완전한 통제를 할수록 더 인위적인 상황이 연출됨; 자연스러운/현실적인 상황에서 적용된다는 보장이 없음
- 실험 참여자는 어떻게 왜 참여한 것인가?
Case 1
Terror Management Theory (TMT)
Self-esteem의 이론적 근거를 밝히고자 함. 왜 인간은 self-esteem을 유지하려는가?

Treatment: 자신의 죽음과 고통에 대해 생각해보고 써보도록 하고
Control: 자신의 치통에 대한 질문에 답
측정: 고정관념에 대해 부정적으로 말하는 사람을 어떻게 평가하는가?
결과: 그들을 더 부정적으로 평가: defences their own culural worldview
(e.g. Stereotypes and Terror Management: Evidence That Mortality Salience Enhances Stereotypic Thinking and Preferences)
- 죽음이나 치통에 대한 생각은 모두 두려움을 포함해 부정적 감정을 불러 일으키는데
- 그저 두려움에 대한 반응인가? 아니면 정확히 “죽음에 대한 생각”이 효과를 만든 것인가?
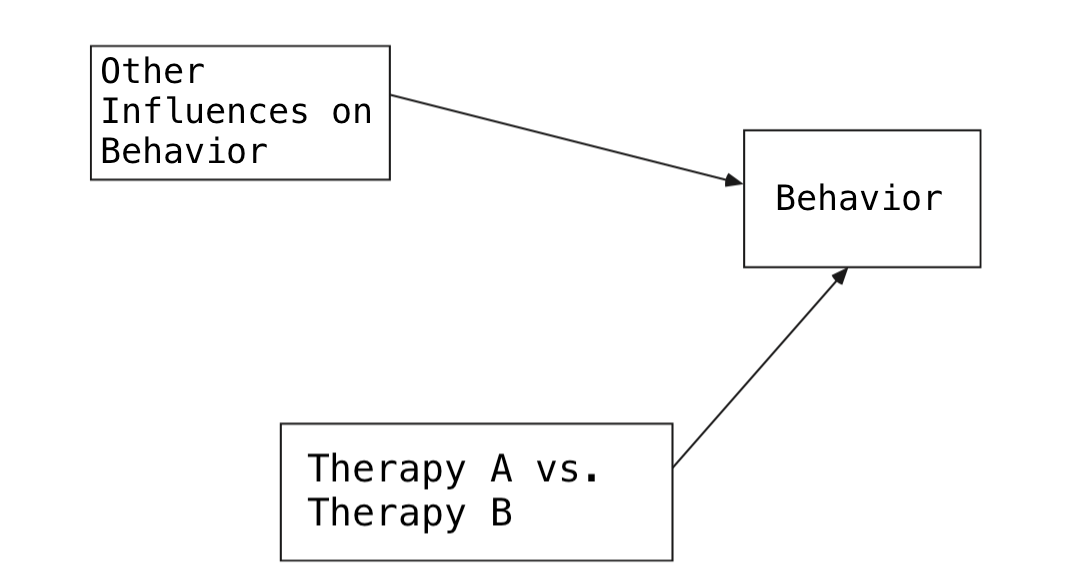
- 참여자들의 부정적 정서를 실험 마지막에 측정한 후 분석에 고려했음; covariate
Important
연구 설계시 관심이 있는 효과를 효과적으로 측정하는 것과 동등하게 중요한 것은 어떤 confounding들이 존재할 수 있는지를 다각도로 검토한 후 이를 설계에 반영하는 것임.
예를 들어, 위의 경우 죽음에 대한 생각 자체의 효과가 아닌 죽음을 생각했을때 발생할 수 있는 부수적인 감정들로 인해 효과가 난 것이 아닌가하는 것들을 고려해서 설계할 수 있음.
Case 2
마시멜로우 실험, 1960’s

Source: Want To Teach Your Kids Self-Control?
3-5세 아이들에게 마시멜로우 1개를 놓고 원하면 먹도록 하나, 만약, 5분을 안먹고 기다리면 2개를 먹을 수 있다고 말한 후, 기다리지 못하고 먹는지를 살펴봄
소위 delay gratification을 self-control을 발휘한 것으로 이해했으며, 먹지 않고 기다린 아이들이 추후에 학업성취도 및 여러면에서 뛰어난 결과를 보고 하였음.
- 아이들이 참고 기다린 것은 자력에 의한 자기통제력인가?
- 어른들 즉, 권위에 대한 복종인가?
- 더 많이 먹기 위한 욕심인가?
- 눈 앞에 이익을 빨리 취하는 것은 좋은 전략일 수 있지 않은가?
- 제3의 common cause가 있을 수 있는가? 지능? 양육 스타일?
혹시 실험을 진행하는 실험자에 따라 다른 효과가 나타날까? (Experimenter effects)
처치(treatment)의 효과인가 처지가 일어나는 상황이 만든 효과인가?
Important
이 연구에서도 여러 confounding들을 생각해볼 수 있음
위에서 언급한 것들 외에 어떤 것들이 있을까?
적어도 마시멜로우 실험의 경우에서 아이들에게 기다리라고 지시한 experimenter들의 정보를 고려할 필요가 있음.
그럼, 각 experimenter별로 자료를 분석해야 하는가?
좀 더 확장하면,
- 같은 처방을 내린 의사들에 따라 다른 효과가 나타날까?
- 의사가 속한 병원마다 다른 효과가 나타날까?
- 특정 수업방식의 효과가 학교마다 선생님마다 다르게 나타날까?
Note
Multi-level analysis (mixed effect model)
이는 위에서 언급한 longitudinal (종단) 데이터가 지닌 관측치의 dependency를 고려하는 일반적인 접근임. 관측치들이 군집을 이루면서 군집끼리 비슷한 경향을 보인다면, 이를 고려한 분석이 요구됨. 보통 dependency는 데이터를 어떻게 수집했는지를 알아야 파악할 수 있으며, 데이터 내에서 찾아내기 어려움. (clustering analysis 같은 machine learning 분야에서 개발되는 알고리즘적 분석들이 있음)
만약, 군집을 이루는 단위가 충분히 많다면,
예를 들어, 10개의 병원에서 30명의 의사가 각각 50명의 환자에게 새롭게 개발된 처방을 처치하여 그 효과를 볼 때,
- 병원의 효과 vs. 의사의 효과 vs. 처치의 효과를 분리하여 좀 더 분명한 효과를 찾을 수 있음
또는, 30개의 학교에서 50명의 선생님들이 30명의 학생들에게 특정 수업방식의 효과를 검증할 때,
- 학교의 효과 vs. 선생님의 효과 vs. 수업의 효과를 분리해 볼 수 있음
분석을 위해 각 선생님 마다 혹은 학교마다 따로 분석하는 것도 아니며, 학교별 혹은 선생님별 특성을 측정하여 고려한다든가 하는 방식이 아님. 자료가 품고 있는 관측치들의 유사성이 통계적으로 파악되어 고려되는 것으로, 모든 샘플을 동시에 이용한 고급 통계 방법
사회과학 자료에서도 만일 가족단위로 데이터 수집이 이루어진다면, 가족 간의 무언가 톡특한 특성이 연구결과에 반영될 수 밖에 없는데, 가족의 특성을 분리해야 연구자가 살펴보는 관심 변수들 간의 관계를 올바로 파악할 수 있음. 다시 지적하면, 연구에서 가족의 특성을 직접 측정해서 고려한다는 의미가 아니고, 자료가 품고 있는 가족간의 유사성이 통계적으로 파악되어 고려되는 것임.
Case 3
상담치료 (dialectical behavior therapy)에 대한 효과 검증
Zeifman, R. J., Boritz, T., Barnhart, R., Labrish, C., & McMain, S. F. (2020). The independent roles of mindfulness and distress tolerance in treatment outcomes in dialectical behavior therapy skills training. Personality Disorders: Theory, Research, and Treatment, 11(3), 181.
연구 절차
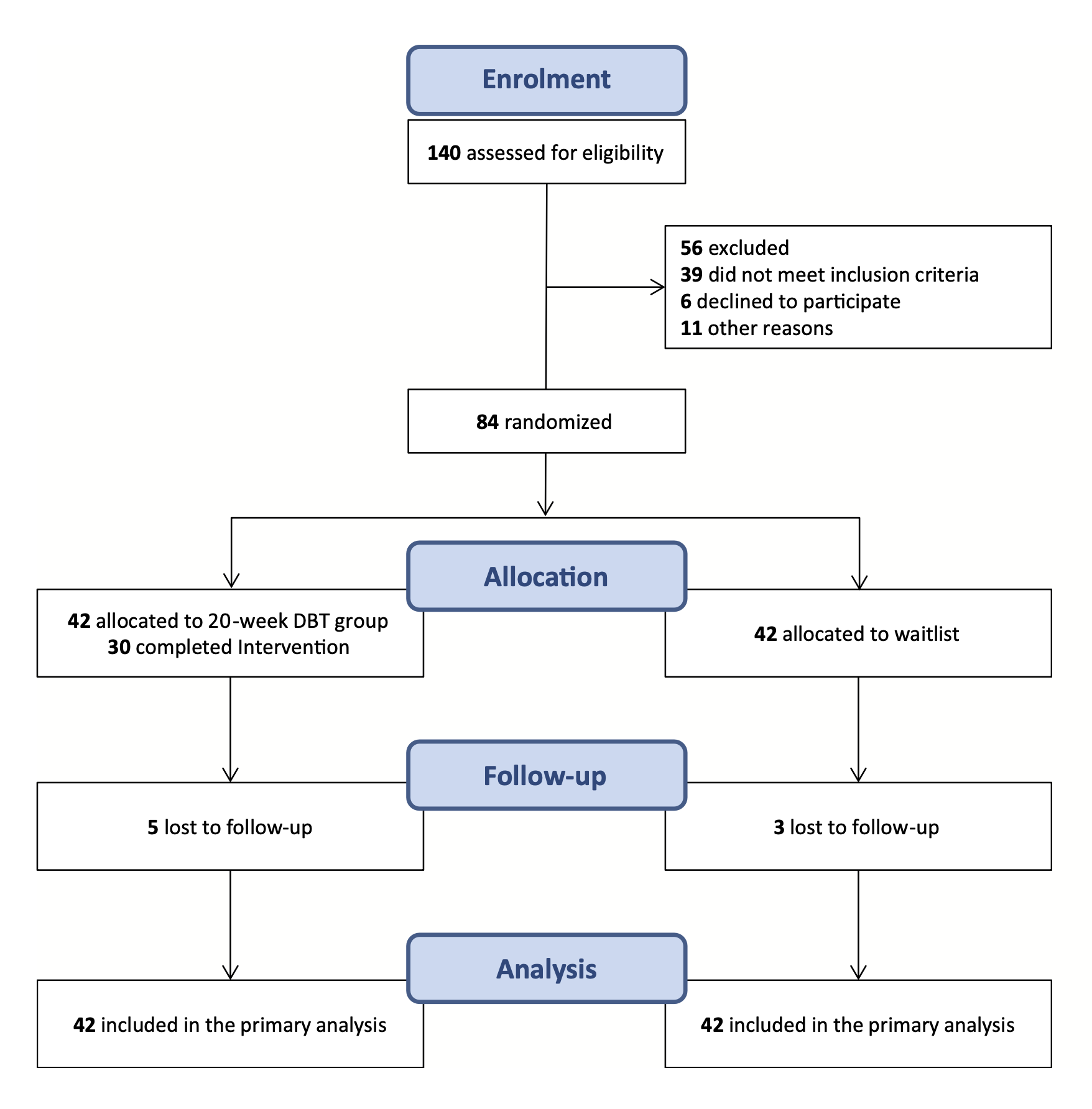
연구 설계
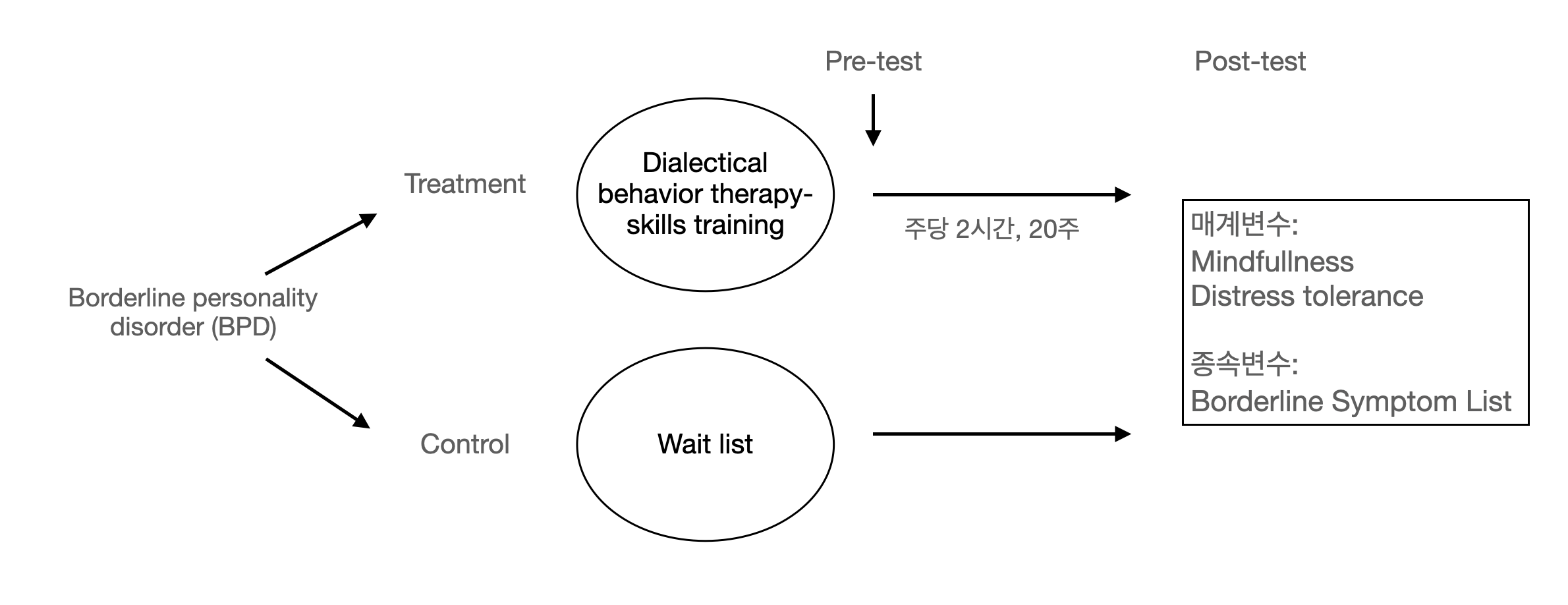
치료 효과에 대한 모형
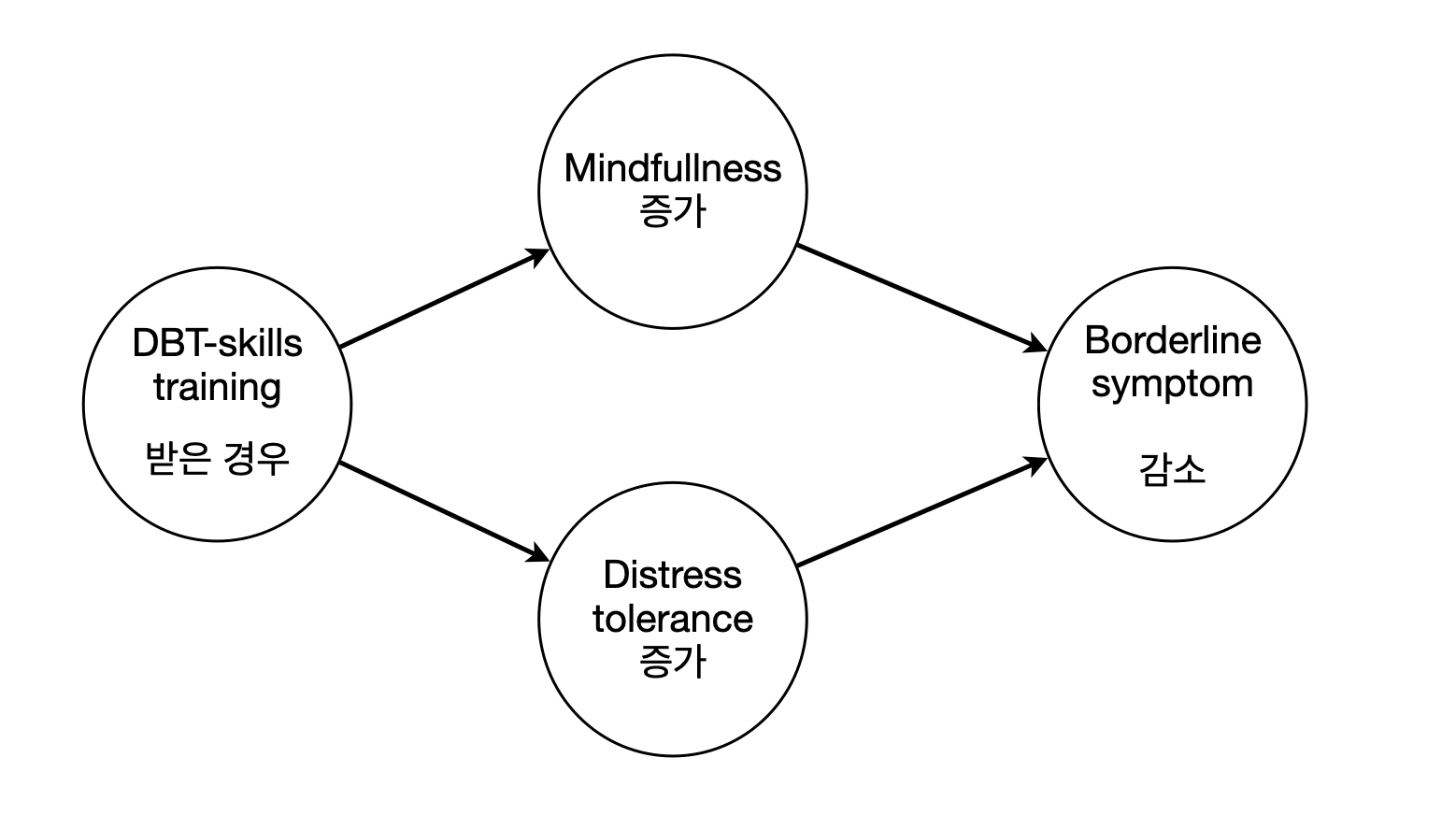
- 정말 DBT 치료의 효과인가?
- 아무런 처지도 하지 않은 통제집단은 적절한가?
- 매개변수의 효과(매커니즘)를 추론할 수 있는가?
- 경계성 인격장애의 기준이 문제가 되지 않는가?
- 경계성 인격 장애의 정도가 치료 효과에 영향을 미치지 않는가?
- 이 연구결과는 어떤 대상으로 일반화될 수 있는가?
- 20주를 다 채우지 않은 참여자들에 대해서 문제가 되는가?
- 표본의 수가 충분한가?
Case 4
요양원의 노인들을 대상으로, 독립적 행동의 기회 증가가 그들의 정신 건강에 미치는 영향
Langer, E. J., & Rodin, J. (1976). The effects of choice and enhanced personal responsibility for the aged: A field experiment in an institutional setting. Journal of Personality and Social Psychology, 34, 191–198.
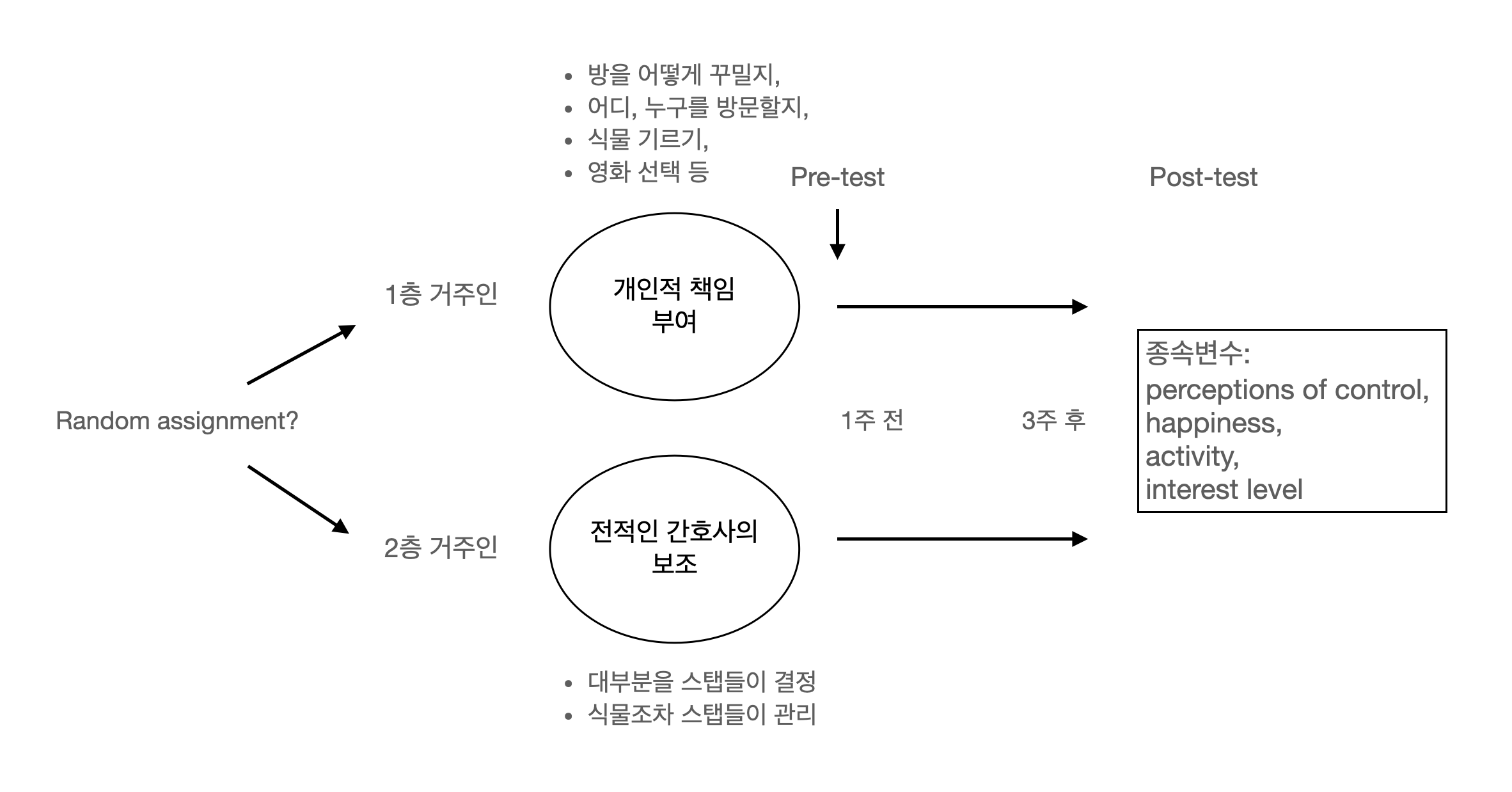
- 두 층의 노인들의 특성은 동일한가?
- pretest에서 두 그룹 간의 특성이 유사한지에 대한 체크 문항: 모두 측정할 수는 없음!
- 간호사 스탭들의 효과?
- 두 층의 할당된 간호사들의 차이?
- 스텝들 자신들도 변화된 요양원의 지침에 반응했는가? 또한 그 변화에 노인들도 반응했는가?
- 두 층에서 동일하게 활동이나 환경의 변화가 일어났는가? 예, 간호사의 변경
- 두 층의 노인들 간의 교류? 오염 요인
- 구체적으로 어떤 요인이 효과를 낸 것인가?
- “treatment package”
- 갑작스러운 변화 자체?
- 이 요양원에 들어온 노인들의 특성이 있는가?
- 사회경제적 수준이 높은 노인들의 경우 독립적 생활에 대한 더 긍정적 효과가 발현?
- 다른 특성의 요양원의 노인들에게도 적용가능한가?
Note
설문(서베이)을 통한 실험연구도 온라인 서베이 툴이 발전함에 따라 용이해졌음.
- 가령, 300명의 참여자들이 온라인 설문에 참여했을 때, 참여자의 1/3 각각에 대해 서로 다른 설문 세트 A, B, C가 무작위로 배정되도록 할 수 있으며,
- 각 설문 세트에서도 인터랙티브하게 조건에 따라 다른 문항들에 노출되도록 할 수 있음.
- 대표적인 서베이 툴: Qualtrics
- 온라인 서베이 참여자 풀: M-turk, Prolific
Uncertainty
관찰자가 관찰한 대상으로부터 얻은 결과를 관찰하지 않은 더 넓은 대상으로 일반화할 수 있는가?
가령, 다음과 같이 150명에 대해 조사한 “연령이 임금에 미치는 효과”를 일반화 할 수 있는가?
한 나라의 국민 전체?
Statistical inference (통계적 추론)
통계학의 추론(statistical inference)은 작은 샘플(sample)로부터 얻은 분석 결과를 바탕으로 모집단(population)이라고 부르는 전체에 대해 말하고자 하는 시도에서 비롯되었음
- 어떤 비료가 특정 콩 A의 재배에 어떤 영향을 미치는지 알기 위해 하나의 sample (N=10000: sampe size) 위에서 실험이 이루어지고, 그 결과가 A라는 콩의 종 전체에 얼마나 적용될 수 있을지를 알아보고자 했음
- 사람에게도 적용될 수 있는가?
사실상 난해한 통계 이론의 상당부분을 차지함.
하지만, 통계적 추론의 논리는 개념적으로는 다음과 같이 볼 수 있음.
앞서 논의한 모든 내용은 “특정 샘플” 내에서 변수들 간의 관계에 대한 분석일 뿐 그 샘플을 벗어나서 논의한 것이 아님. 통계적 추론은 수많은 같은 수의 샘플들, 가령 N = 150인 즉, 150명으로 이루어진 샘플들을 반복적으로 관찰한다면 그 샘플들 간의 편차들이 어떠하겠는가에 대한 논의임.
- 첫번째 그림에서처럼 (알수는 없지만) 어떤 모집단(population)을 가정하는데, 그 모집단에는 남녀 간의 시간당 임금(wage)의 차이에 대한 true relationship이 존재한다고 가정함.
- 연구자가 한번에 150명으로 이루어진 표본(sample)을 반복적으로 관찰한다면, 표본마다 남녀 간의 임금 격차는 다르게 나타날 것임 (두번째 그림).
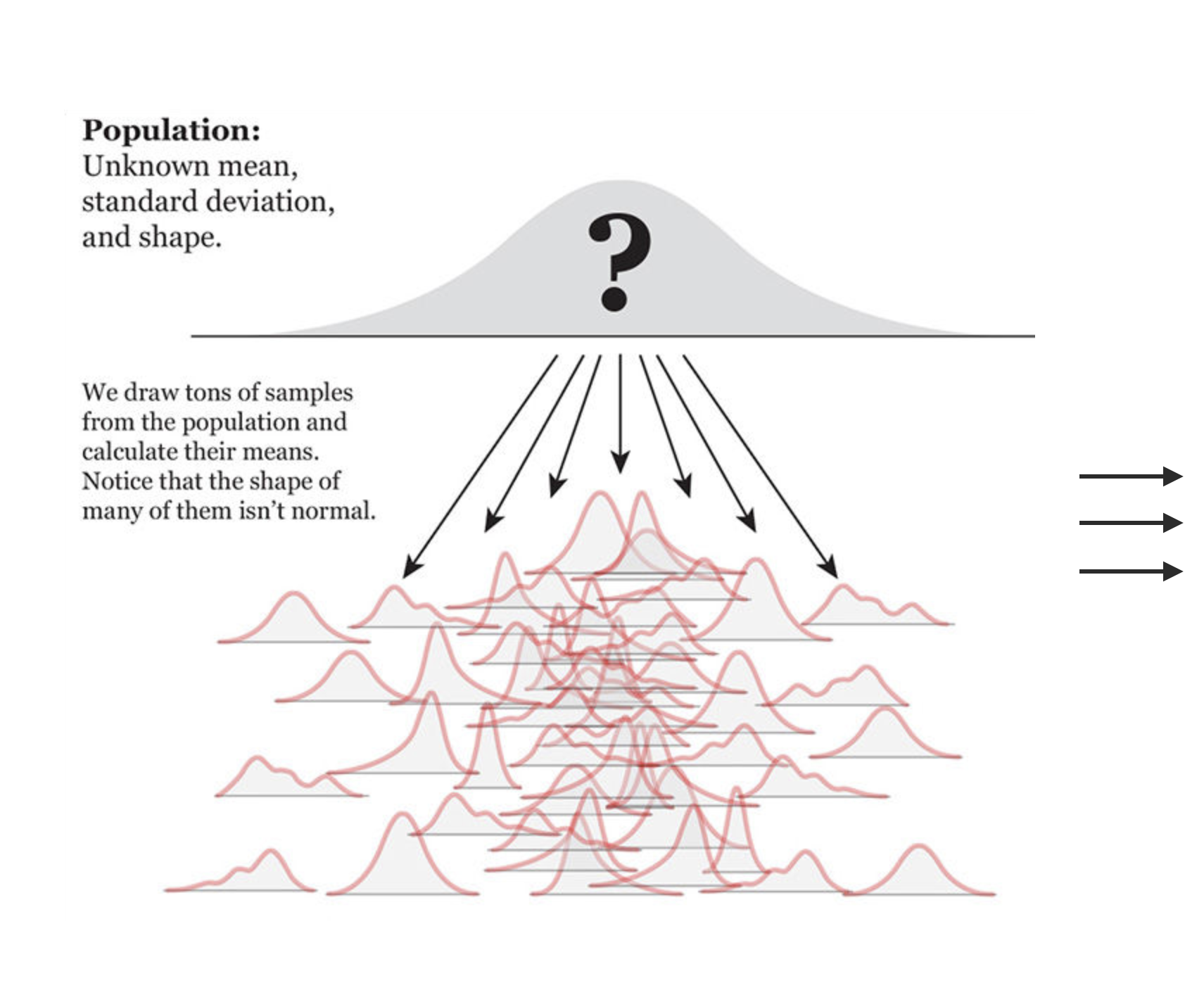
Source: The Truthful Art by Albert Cairo.
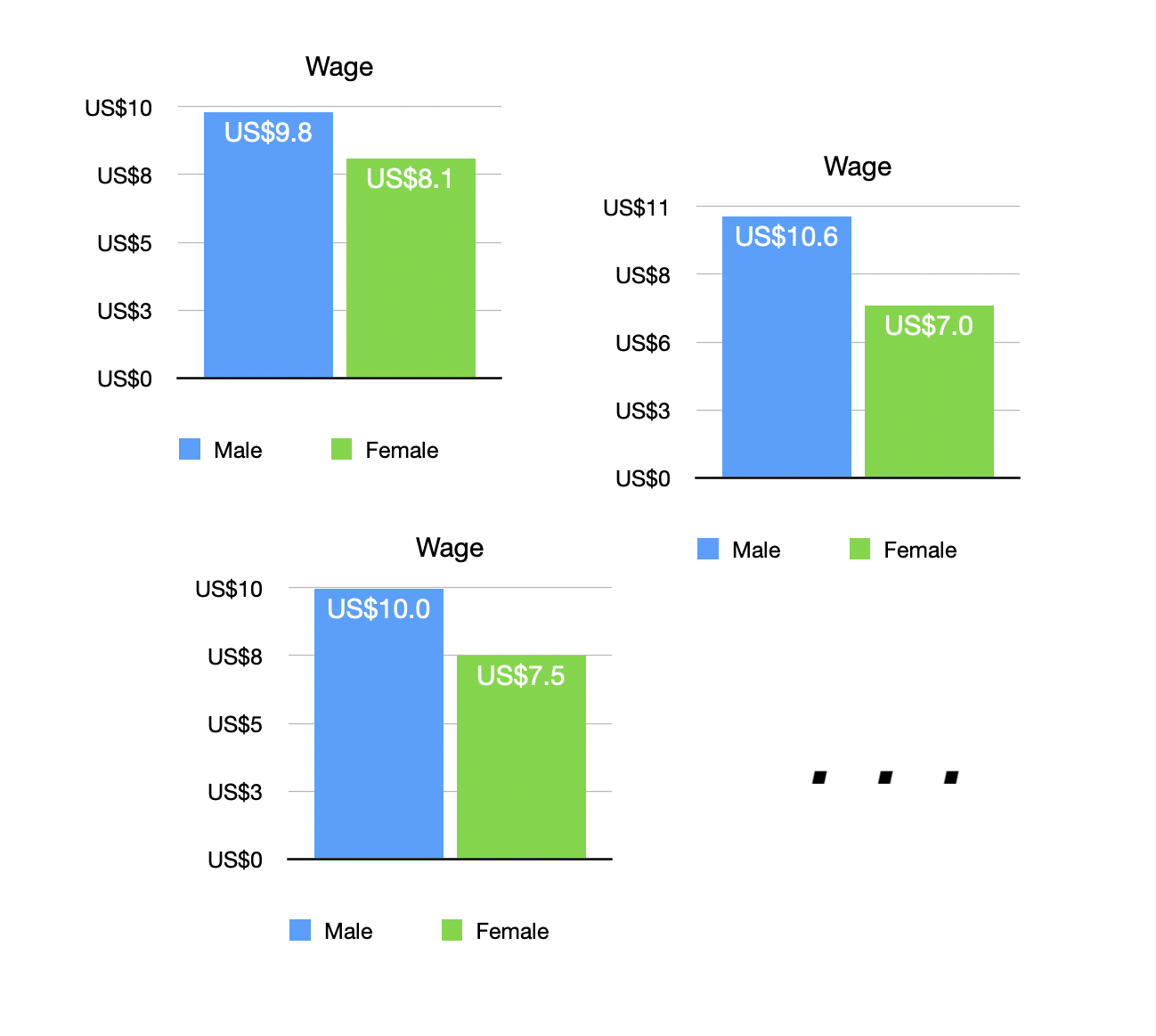
- 샘플들로부터 나타나는 임금 차이 값의 분포를 살펴봄으로써 샘플에서 나타날 수 있는 남녀 간의 임금 차이가 어떠한가를 파악할 수 있음.
- 이 분포를 sampling distribution(표본 분포)이라고 부름
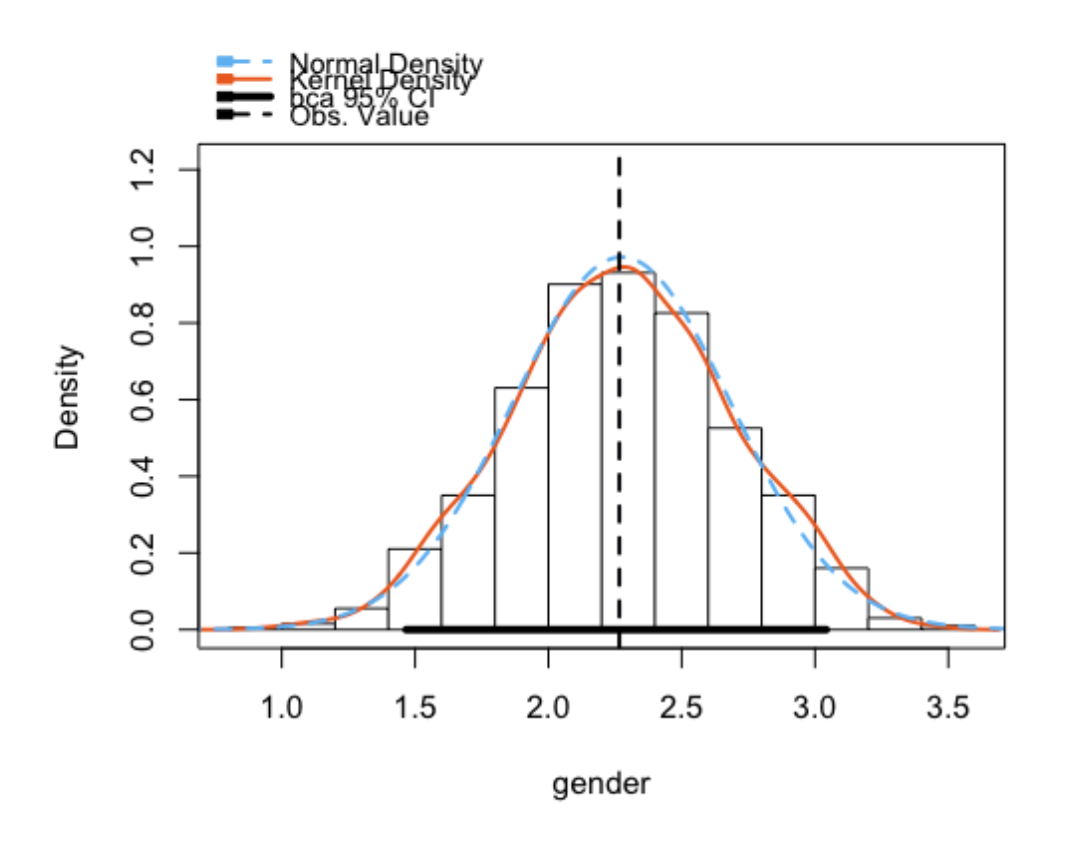

- 이 분포에 따르면 평균이 $2.27이고, 임금 차이 값들의 95%가 $1.47 ~ $3.04 범위에 있음을 알 수 있음.
- 다시말하면, 연구자가 관찰한 샘플로부터 연구자는 매우 큰 확신(95%)을 갖고 남녀의 시간당 임금의 차이는 1.47달러에서 3.04달러 사이에 있을 것이라고 말할 수 있음.
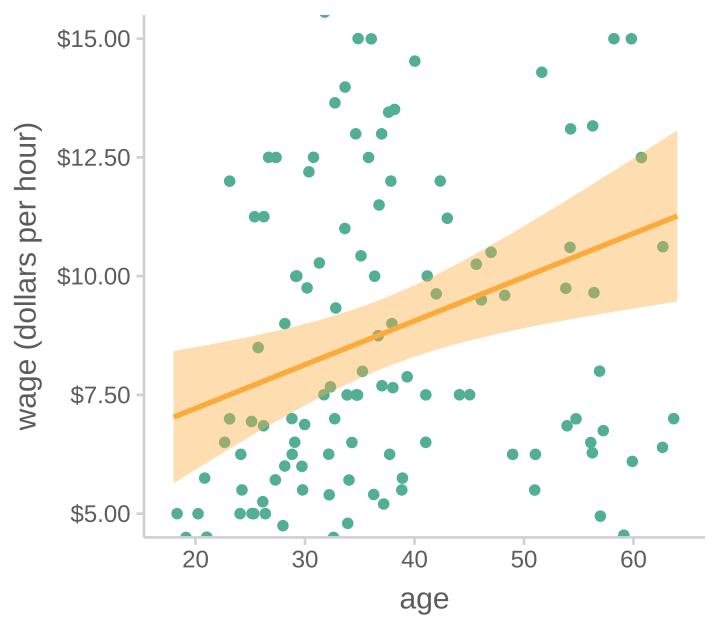
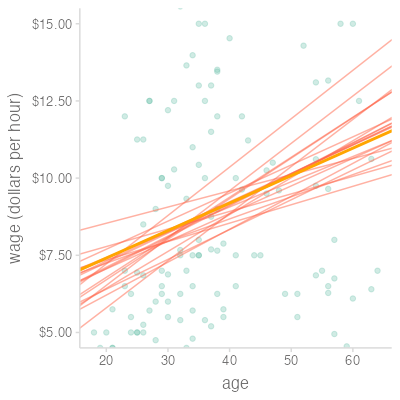
비슷하게, 어떤 모집단에서 나이(age)와 시간당 임금(wage)의 true relationship이 선형적으로 존재한다고 가정했을 때,
연구자가 한번에 150명으로 이루어진 sample을 반복적으로 관찰한다면, 샘플마다 age와 wage의 관계는 다르게 나타날 것임 (두번째 그림).
- 예를 들어, 샘플들로부터 나타나는 기울기들의 분포를 살펴봄으로써 (세번째 그림) 샘플에서 나타날 수 있는 기울기값이 어떠한가를 파악할 수 있음.
- 이 분포를 sampling distribution(표본 분포)이라고 부름
- 이 분포에 따르면 평균이 0.092이고, 기울기 값들의 95%가 0.026 ~ 0.165 범위에 있음을 알 수 있음.
- 다시말하면, 연구자가 관찰한 샘플로부터 연구자는 (age와 wage의 선형성을 가정한다면), 매우 큰 확신을 갖고 나이가 10세 늘때마다 시간당 임금의 증가율은 0.26에서 1.65달러 사이에 있을 것이라고 말할 수 있음.
Source: The Truthful Art by Albert Cairo.
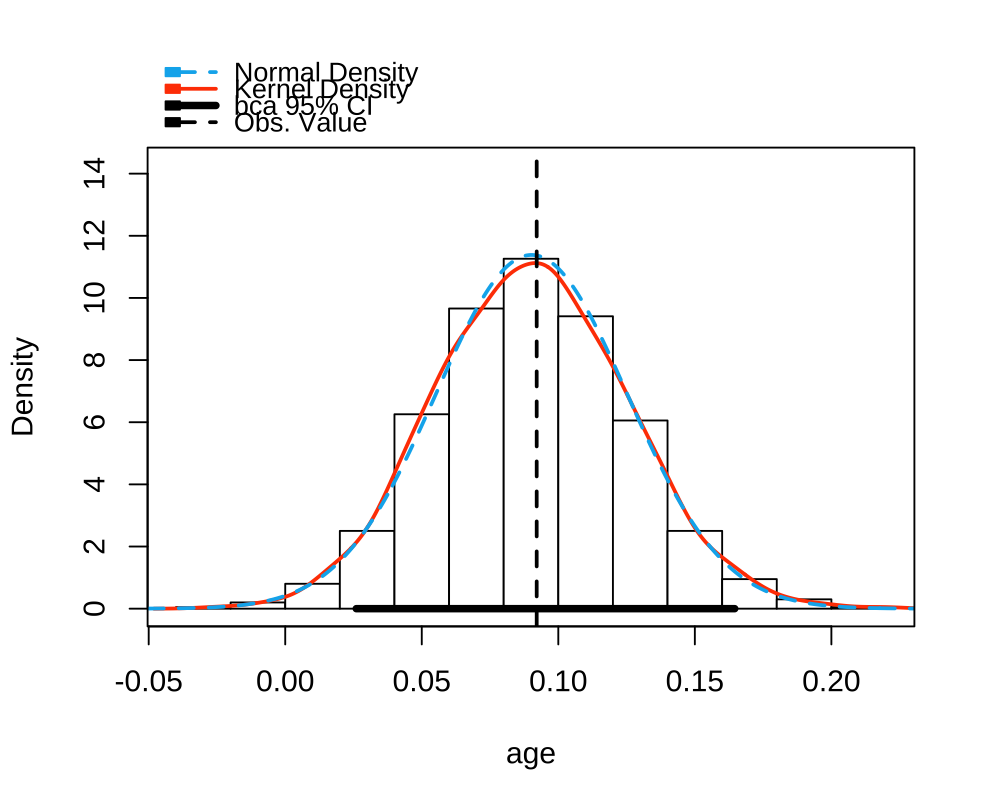
Bootstrap bca confidence intervals
Estimate 2.5 % 97.5 %
(Intercept) 5.375 2.906 7.920
age 0.092 0.026 0.165
Note
위와 같이 어떤 분포를 가정하고 파라미터(기울기 등등)를 포함해 상정한 모델에 대한 통계적 추정과 추론을 하는데 대한 비판이 오래전부터 있어왔음. 현실의 실제적 현상에 적용할 때는 이론적인 통계의 원리와는 별개의 더 깊은 논의가 필요함.
e.g:
Breiman, L. (2001). Statistical modeling: The two cultures (with comments and a rejoinder by the author). Statistical science, 16(3), 199-231.
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129-133.
Pearl, Judea, and Dana Mackenzie. 2018. The Book of Why: The New Science of Cause and Effect. Basic books.
Regression analysis
앞서 다뤘던 임금과 연령의 관계에 대한 간단한 회귀 분석의 예들
- 선형 관계를 가정한 임금과 연령의 관계에 대한 회귀분석 (N=150)
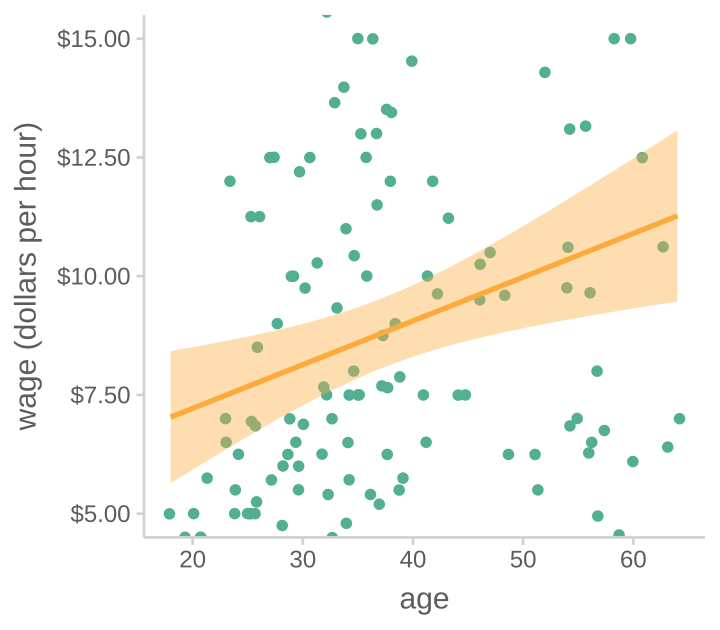
Model: lm(wage ~ age, data = cps)
MODEL INFO: Observations: 150 Dependent Variable: wage Type: OLS linear regression MODEL FIT: F(1,148) = 8.755, p = 0.004 R² = 0.056 Adj. R² = 0.049 Standard errors:OLS ---------------------------------------------------------- Est. 2.5% 97.5% t val. p ----------------- ------- ------- ------- -------- ------- (Intercept) 5.375 2.970 7.780 4.417 0.000 age 0.092 0.031 0.154 2.959 0.004 ----------------------------------------------------------
- 맨 처음 든 예, 즉 연령을 고려한/통제한 “기혼여부에 따른 임금차이”를 회귀분석하면 (N=465)
우선, 결혼여부에 따른 평균 임금의 차이는 미혼일 때 -0.97 (dollars/hr) 낮음.
하지만, 모집단에서 그 차이는 (95% 확률로) -1.93에서 -0.02 사이에 있을 것이라고 추정할 수 있음
Model: lm(wage ~ married, data = cps)
MODEL INFO: Observations: 533 Dependent Variable: wage Type: OLS linear regression MODEL FIT: F(1,531) = 8.34, p = 0.00 R² = 0.02 Adj. R² = 0.01 Standard errors:OLS ----------------------------------------------------------- Est. 2.5% 97.5% t val. p ------------------- ------- ------- ------- -------- ------ (Intercept) 9.40 8.89 9.91 36.07 0.00 marriedSingle -1.28 -2.16 -0.41 -2.89 0.00 -----------------------------------------------------------
앞서 논의한데로 나이가 confounding이 될 수 있고,
이를 통계적으로 통제하면,
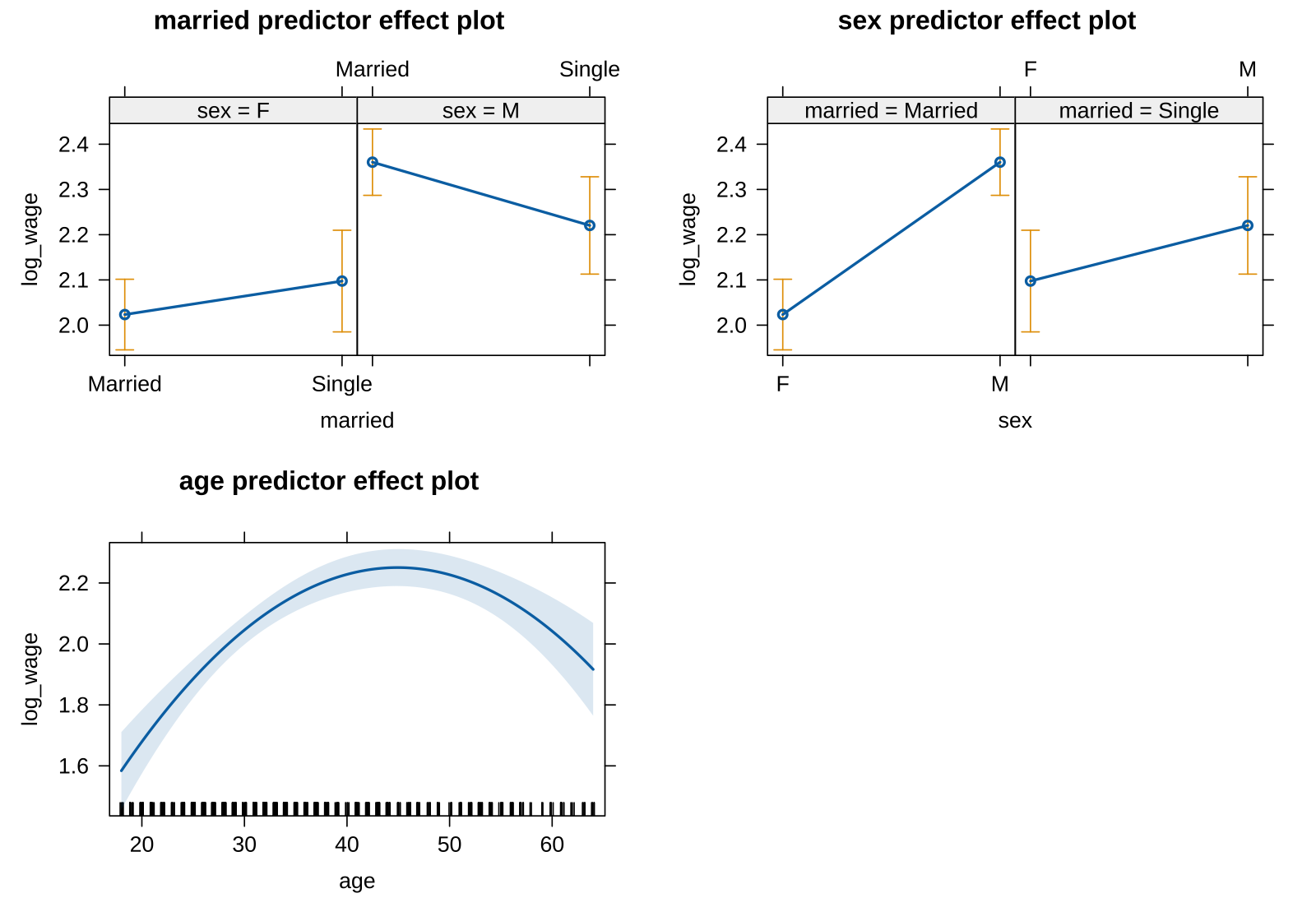
Model: lm(wage ~ married + sex + age + I(age^2), data = cps)
MODEL INFO: Observations: 533 Dependent Variable: wage Type: OLS linear regression MODEL FIT: F(4,528) = 23.70, p = 0.00 R² = 0.15 Adj. R² = 0.15 Standard errors:OLS ------------------------------------------------------------ Est. 2.5% 97.5% t val. p ------------------- ------- -------- ------- -------- ------ (Intercept) -6.43 -10.87 -2.00 -2.85 0.00 marriedSingle -0.17 -1.04 0.70 -0.38 0.70 sexM 2.44 1.67 3.22 6.18 0.00 age 0.68 0.46 0.91 5.95 0.00 I(age^2) -0.01 -0.01 -0.00 -5.26 0.00 ------------------------------------------------------------
“나이를 고려했을 때”, 미혼이 기혼보다 그 임금이 0.17 (dollars/hr) 낮은데,
모집단에서 그 차이는 -1.04 ~ 0.70 사이에 있을 확률이 매우 높은 것으로 추론됨. (95% 확률로)
이는 사실상 임금 차이가 있다고 볼 확신을 거의 갖기 어려움
결혼여부와 성별이 상호작용하는 것을 고려하고, 임금의 분포를 고려해서 log 변환하면,
Model2: lm(log_wage ~ married * sex + age + I(age^2), data = cps)
MODEL INFO: Observations: 530 Dependent Variable: log_wage Type: OLS linear regression MODEL FIT: F(5,524) = 25.06, p = 0.00 R² = 0.19 Adj. R² = 0.19 Standard errors:OLS ---------------------------------------------------------------- Est. 2.5% 97.5% t val. p ------------------------ ------- ------- ------- -------- ------ (Intercept) 0.23 -0.23 0.68 0.98 0.33 marriedSingle 0.07 -0.05 0.20 1.17 0.24 sexM 0.34 0.24 0.43 6.82 0.00 age 0.08 0.06 0.11 7.06 0.00 I(age^2) -0.00 -0.00 -0.00 -6.45 0.00 marriedSingle:sexM -0.21 -0.38 -0.05 -2.51 0.01 ----------------------------------------------------------------
Note
나이와 임금의 관계가 위의 플랏에서 나타났듯이 35세부터 일정하게 유지되는 패턴을 보이므로 그 비선형성을 단순화하여 2차 함수 꼴\((y=c+b\cdot age+a\cdot age^2)\)로 모델링을 하였으나 원칙적으로는 다른 모형이 필요함
회귀모형의 확장
Generalized Linear Model (GLM): 정규분포가 아닌 종속변수에 대한 회귀분석
- 완치 여부(success vs. fail), 구매 여부(yes vs. no); logistic regression
- 사건 또는 사람의 수 (count): poisson regression
Mixed-effects model: 관측치들에 dependecy가 존재하는 경우
- Multi-level 분석
- 종단데이터 분석